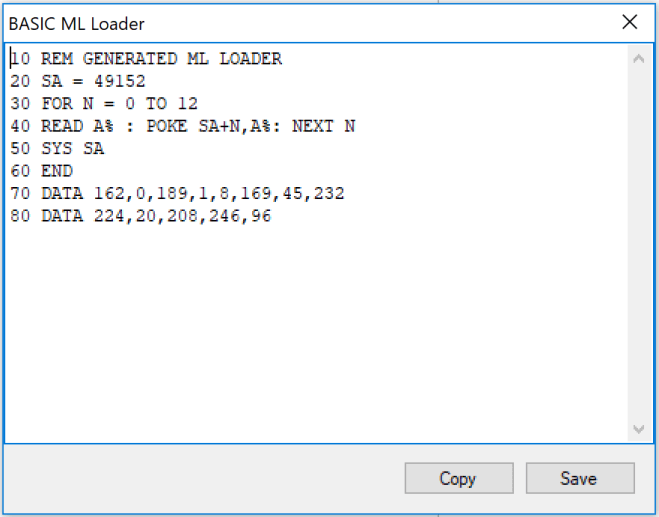
En el modo bitmap, la pantalla no está organizada en caracteres, sino que está organizada en pixels individuales. En el fondo, la pantalla tiene la misma resolución que en el modo carácter, lo que pasa es que cada pixel se maneja independientemente de los demás.
Por tanto, si en el modo carácter la resolución es de 25 x 40, siendo los caracteres de 8 x 8 pixels, al eliminar las fronteras entre caracteres lo que tenemos son 200 x 320 pixels. Y cada uno de estos pixels se puede activar / desactivar de forma independiente de los demás, y sin formar parte de un carácter. Por supuesto, la información para ello sigue saliendo de la memoria RAM, pero ya no de la RAM de pantalla ($0400 – $07e7), como se verá enseguida.

Así como en el modo carácter la RAM de pantalla ocupa 1.000 bytes, en el modo bitmap tenemos 200 x 320 = 64.000 pixels. Por tanto, necesitamos 64.000 bits o, lo que es lo mismo, 8.000 bytes. Es decir, en el modo bitmap la información que define la pantalla necesita mucha más memoria que la que cabe en la RAM de pantalla. Esto es totalmente lógico, ya que en el modo carácter despachamos cada matriz de 8 x 8 pixels con un byte (un código de pantalla), mientras que en el modo bitmap necesitamos 8 bytes, exactamente 8 veces más.
El color del bitmap sale de la RAM de pantalla (ojo, no la RAM de color). Cada bloque de 8 x 8 pixels toma sus colores del “carácter” que ocuparía la posición análoga en la RAM de pantalla. Los bits activos (los que están a 1) toman su color del nibble más significativo, y los bits inactivos (los que están a 0) toman su color del nibble menos significativo. Con un nibble se pueden codificar los 16 colores que soporta el C64.
El modo bitmap se activa activando el bit 5 del registro $d011. Este registro también se utiliza para activar el modo carácter con color de fondo extendido (bit 6) y para el bit más significativo del raster (bit 7).
Por último, quedan un par de cuestiones para nada triviales: cómo se le indica al VIC dónde están esos 64.000 bits / 8.000 bytes que definen la pantalla y, sobre todo, cuál es la correspondencia entre esos bits y los pixels de la pantalla.
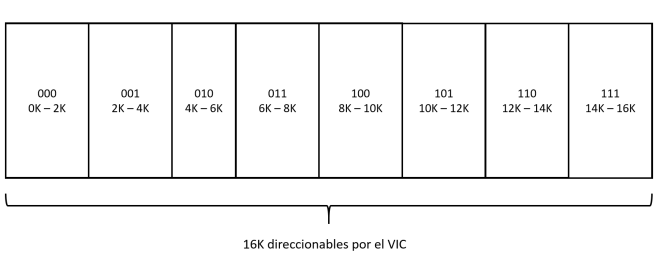
La respuesta a la primera pregunta es actuando sobre el bit 3 del registro $d018, que también se utiliza para indicar dónde se ubican los juegos de caracteres personalizados (bits 1, 2 y 3) y la RAM de pantalla en el modo carácter (también bits 4, 5, 6 y 7). Con el bit 3 pueden indicarse dos valores:
- %0: El bitmap se encuentra en el segmento $0000 – $1fff (0K – 8K).
- %1: El bitmap se encuentra en el segmento $2000 – $3fff (8K – 16K).
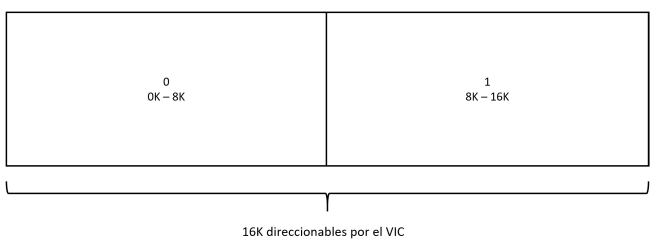
Por supuesto, el segmento de 8K elegido es relativo a la base del banco de 16K direccionado por el VIC. Igual ocurría con los juegos de caracteres personalizados.
Por último, queda explicar cómo es la correspondencia entre los bits de ese segmento de 8K y los pixels de la pantalla. Parecería que lo más intuitivo sería que el primer bit fuera el de la esquina superior izquierda, y así sucesivamente de izquierda a derecha y de arriba abajo, hasta llegar al último de los 64.000 bits, que sería el de la esquina inferior derecha. Pues bien, no es así.
La correspondencia entre los bits de memoria y los pixels de pantalla es bastante más compleja. Es como se indica en la siguiente figura:

Por tanto, como se puede ver en la figura anterior, aunque en el modo bitmap cada pixel es independiente de los demás, el sistema sigue teniendo cierto “tufillo” al modo carácter, ya que los pixels se agrupan y gestionan en bloques de 8 x 8, tanto en pantalla como en memoria. Los pixels activos / inactivos se definen mediante bloques de 8 bytes en memoria. Y su color se define mediante un byte (nibble superior para los bits activos; nibble inferior para los bits inactivos) en la RAM de pantalla.
Sería interesante disponer de alguna herramienta del entorno PC que, dado un diseño de 200 x 320 pixels, generara la definición de memoria anterior. Hasta donde yo sé no existe. O, al menos, yo no la he encontrado en CBM prg Studio.
Por último, las ecuaciones matemáticas trabajan con coordenadas (X, Y). Por tanto, para pintar curvas es interesante disponer de rutinas que, dado un pixel (X, Y), determinen la posición de memoria sobre la que hay que actuar. En el libro “Assembly Language Programming with the Commodore 64”, en sus ejemplos 11-5, 11-6 y 11-7, están explicadas esas rutinas. Además, en el ejemplo 11-8 se muestra cómo usarlas para pintar una especie de estrella.
Programa de ejemplo: Prog44