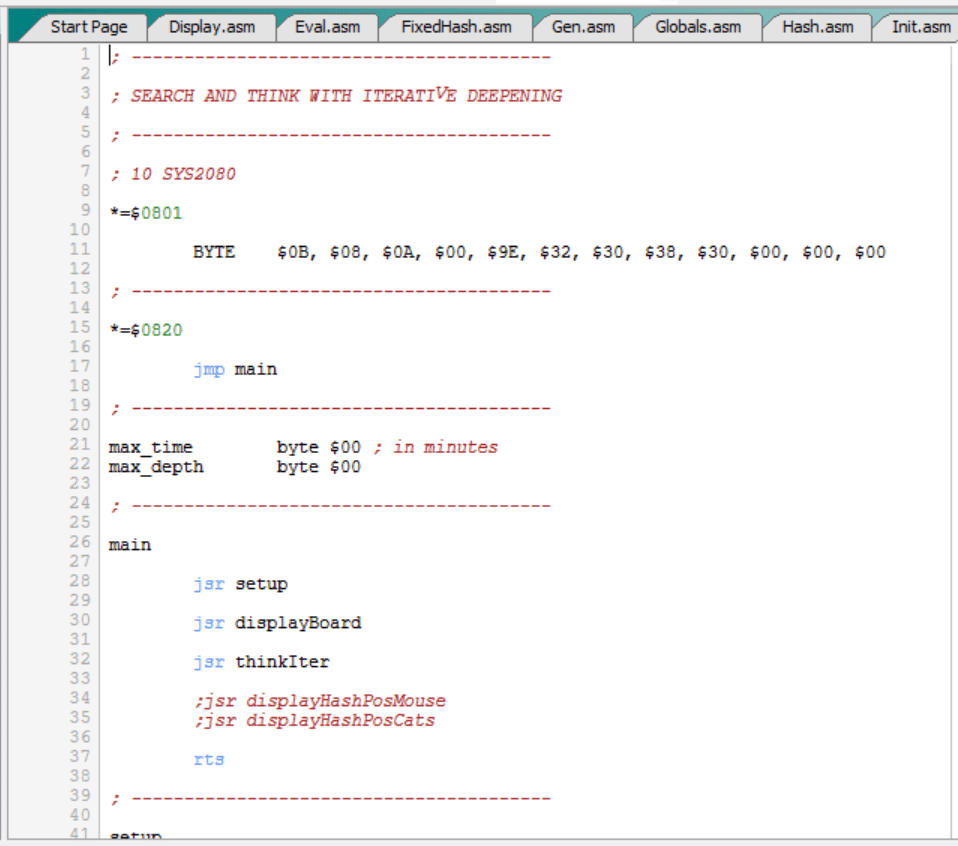
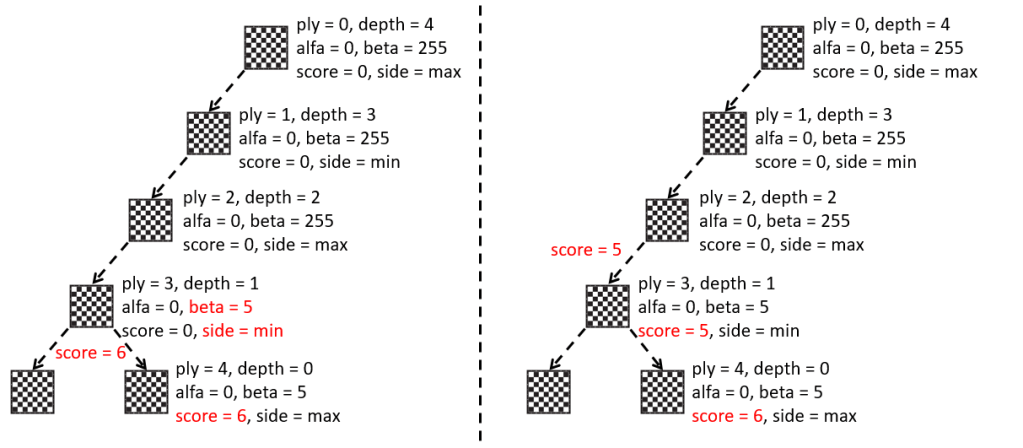
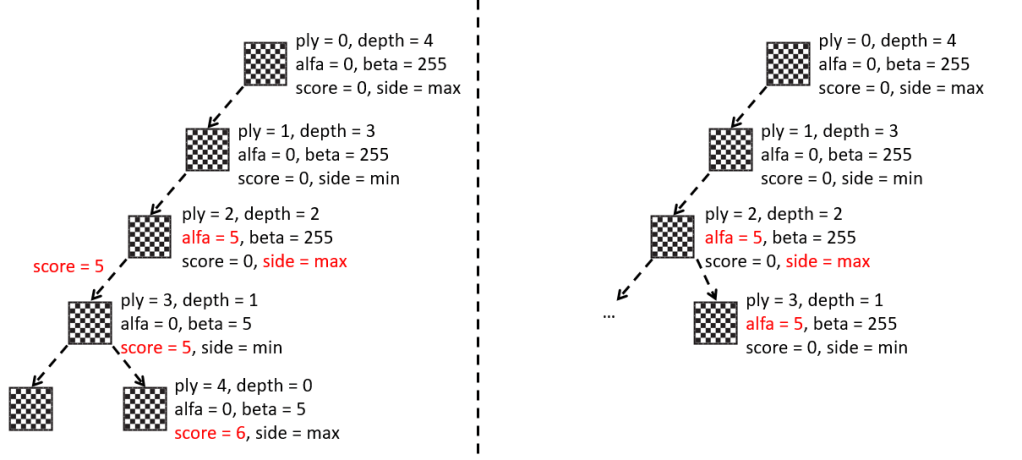
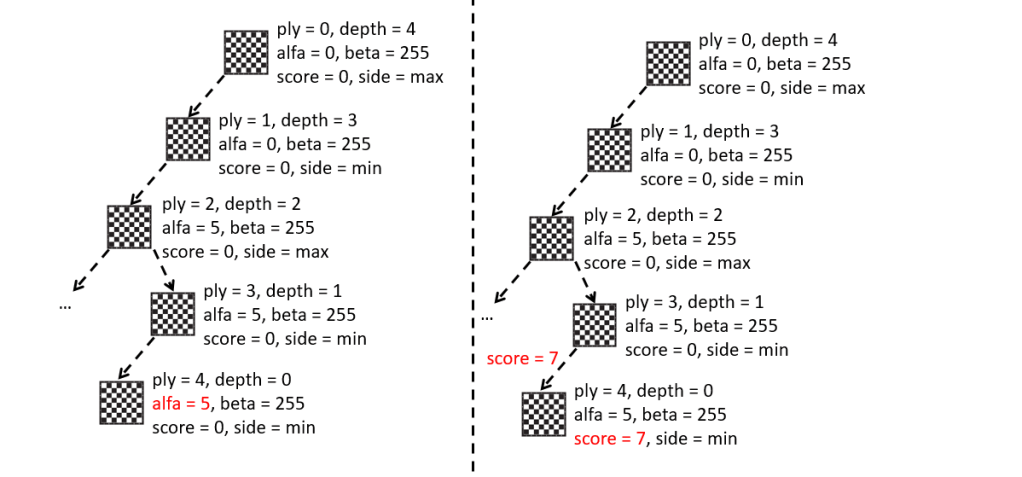
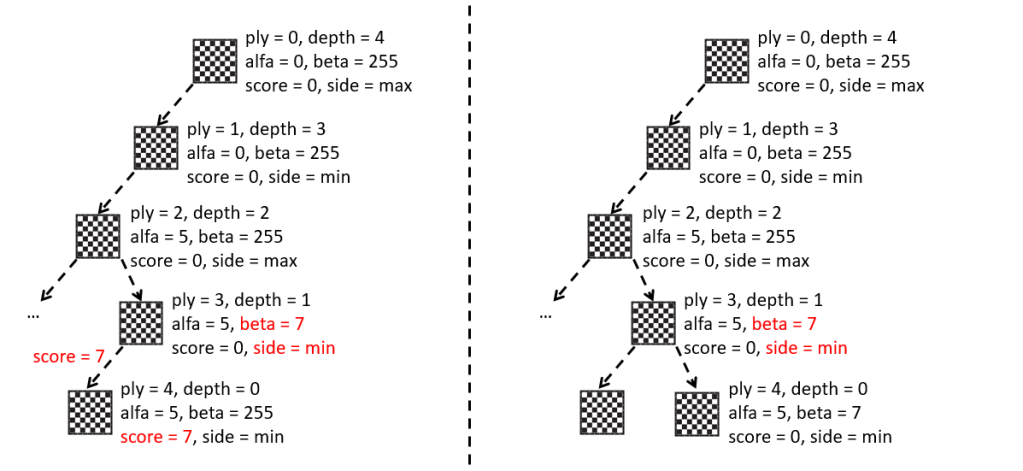
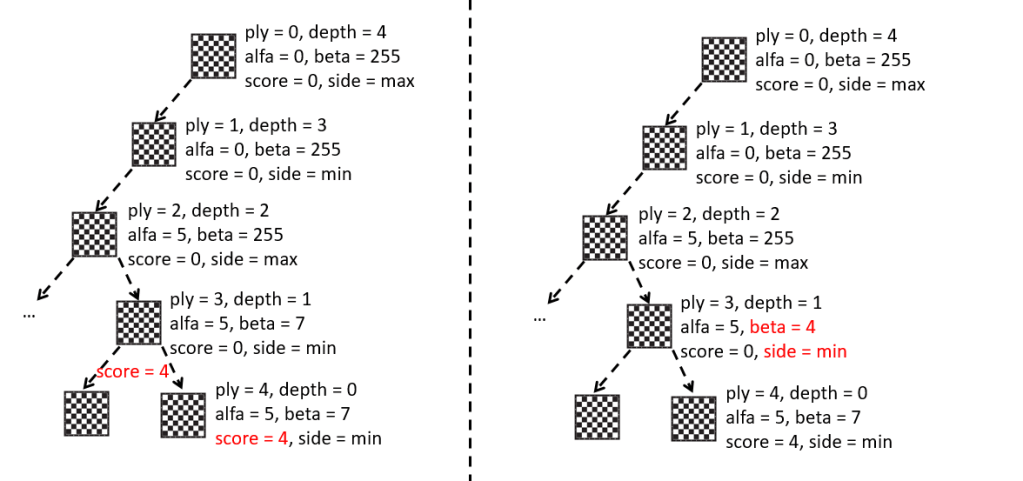
Hasta ahora hemos usado el programa principal, es decir, el fichero “Main.asm”, para probar las diferentes funcionalidades que íbamos desarrollando: la representación e impresión del tablero, la generación de jugadas, las tablas hash de movimientos, la función de evaluación, etc.
Ahora nos disponemos a desarrollar el programa principal definitivo:
Objetivos del programa principal:
Los objetivos de este programa principal serán:
- Ejecutar la configuración inicial del juego.
- Ejecutar el bucle de juego, que consiste en alternar los turnos del jugador uno y del jugador dos hasta que termine la partida.
Normalmente un jugador será el C64 y el otro será un humano, pero también es posible que el C64 o un humano jueguen por ambos bandos a la vez. Esto es muy interesante, porque significa que el C64 podrá jugar contra sí mismo. El humano también, pero para esto casi es más práctico tomar un tablero y unas fichas de verdad 🙂 .
Tanto el C64 como el humano podrán jugar por el bando del ratón o los gatos o, incluso, por ambos, como ya se ha dicho.
Cuando sea el turno del C64, da igual que juegue por el ratón o los gatos, el objetivo será ejecutar la búsqueda alfa – beta hasta la profundidad de análisis configurada, aplicar la jugada elegida, y verificar si es el final de la partida.
Cuando sea el turno del jugador humano, da igual que juegue por el ratón o los gatos, el objetivo principal será aceptar el movimiento del humano, verificar que es un movimiento válido, aplicar el movimiento del humano, y verificar si es el final de la partida.
En caso de que sea el turno del humano, además, se aceptarán una serie de “comandos especiales” para funciones como:
- Mostrar el tablero.
- Arrancar o parar el motor de juego.
- Mostrar la ayuda.
- Mostrar los movimientos válidos.
- Empezar una partida nueva.
- Salir del juego.
- Configurar la profundidad de análisis.
- Configurar el tiempo máximo por movimiento (mejora).
- Cambiar el turno.
- Deshacer la última jugada.
- Etc.
En particular, esta opción de que el humano meta “comandos especiales” puede resultar muy útil para imprimir información que facilite la depuración del programa, como el contenido de las tablas hash, el contenido de las tablas de historia (se verán más adelante), etc.
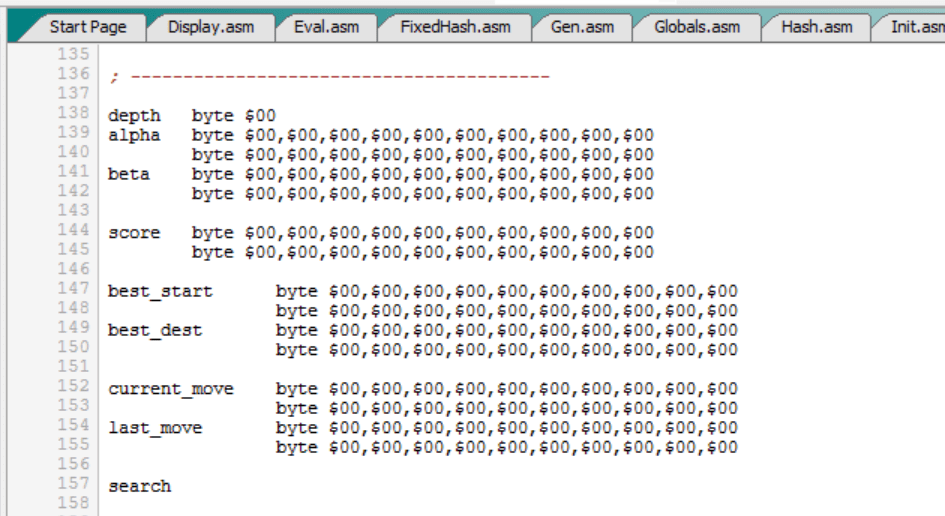
Algunas variables importantes:
Antes de revisar el programa principal, veamos algunas variables importantes:
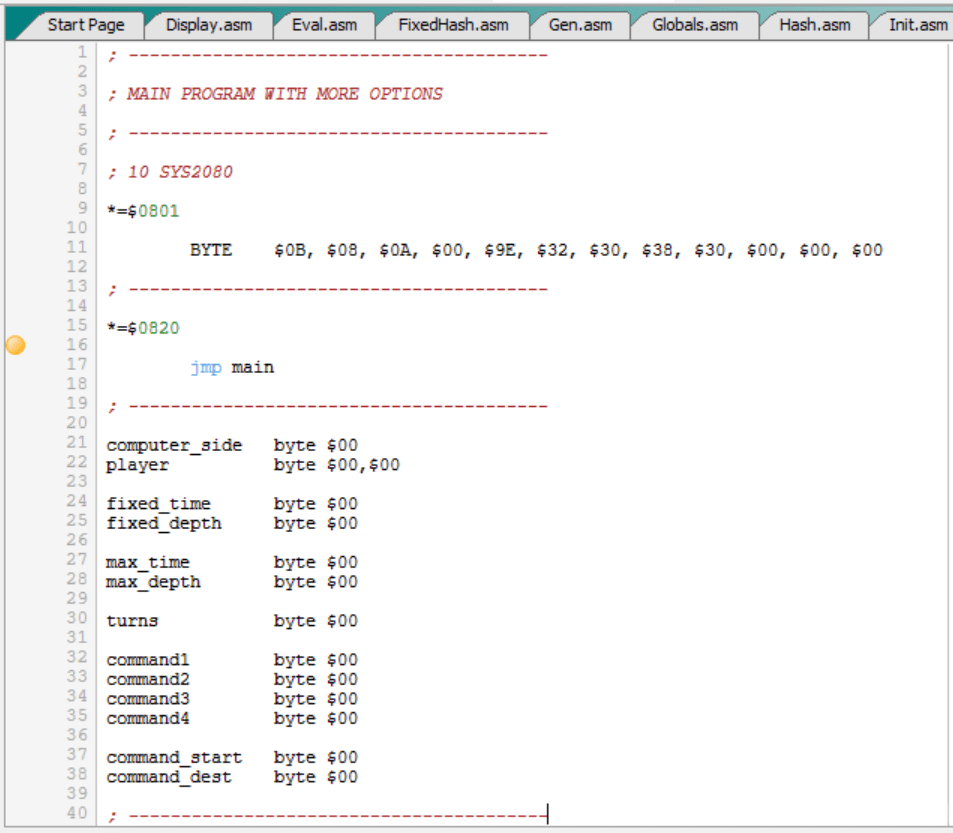
Estas variables se usan para lo siguiente:
- “computer_side”: Permite parar el motor de juego (computer_side = #PIECE_EMPTY), arrancarlo para que el C64 juegue por el ratón (computer_side = #SIDE_MOUSE), y arrancarlo para que el C64 juegue por los gatos (computer_side = #SIDE_CATS).
- “player”: Sirve para llevar control de quién juega por el ratón (valor almacenado en player[#SIDE_MOUSE = 0]) y por los gatos (valor almacenado en player[#SIDE_CATS = 1]). Ambos pueden ser el humano (#PLAYER_HUMAN = 0) o el C64 (#PLAYER_COMPUTER = 1).
- “fixed_time” y “fixed_depth”: Sirven para configurar que el juego juegue a un tiempo fijo por jugada (fixed_time = 1), a una profundidad fija por jugada (fixed_depth = 1), o a ambas cosas, es decir, a la limitación que salte antes (tiempo límite o profundidad límite). De momento sólo está implementada la opción de profundidad fija.
- “max_time” y “max_depth”: Sirven para configurar el tiempo máximo en minutos por jugada y la profundidad máxima en niveles. De momento sólo se utiliza “max_depth” puesto que sólo está implementada esa opción.
- “turns”: Sirve para llevar cuenta del número de jugadas ejecutadas. En realidad, sólo cuenta las jugadas ejecutadas por el C64. Se podrían contar también las jugadas del humano, caso de quererse así.
- “command1” … “command4”: Sirven para almacenar los movimientos y los “comandos especiales” que introduzca el jugador humano. Los movimientos pueden tener hasta 4 caracteres, por ejemplo “E1D2”, que se almacenan respectivamente en command1, 2, 3 y 4.
- “command_start” y “command_dest”: Cuando el comando del jugador humano sea un movimiento del tipo “E1D2”, “E1” se traducirá por la casilla 4, que se almacenará en “command_start”, y “D2” se traducirá por la casilla 11, que se almacenará en “command_dest”. De este modo la información queda lista para ejecutar la rutina “makeMove”.
Todas estas variables controlan el funcionamiento del programa principal.
Programa principal definitivo:
El nuevo programa “main” del fichero “Main.asm” queda así:
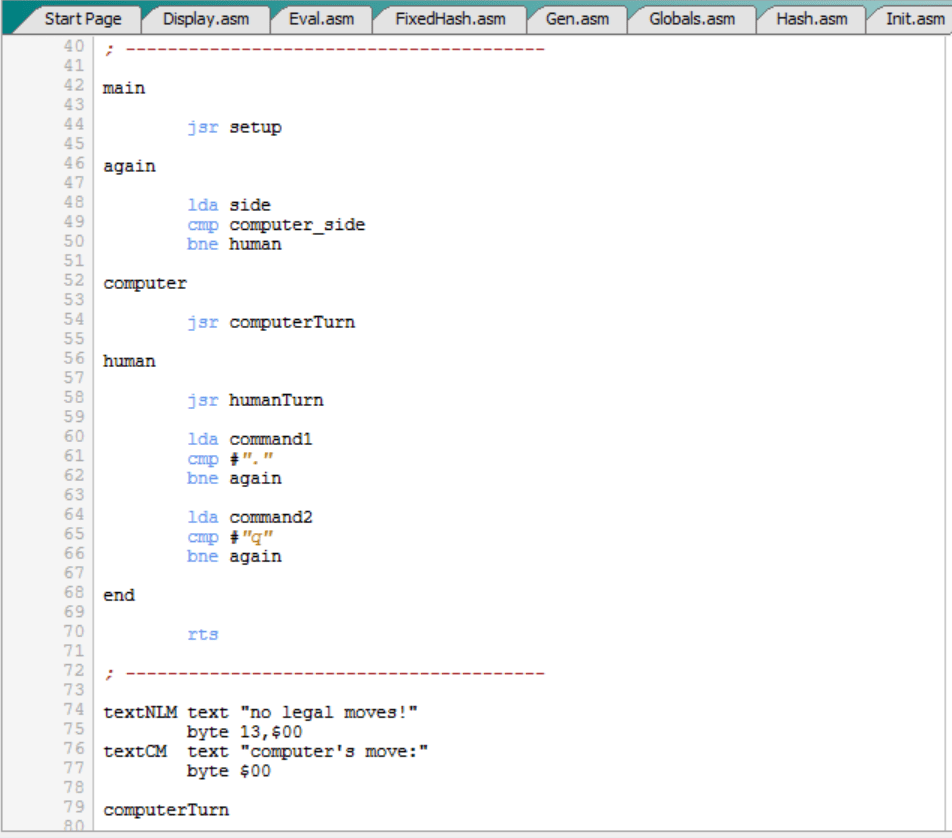
Es decir:
- Primero ejecuta la configuración inicial llamando a la rutina “setup”.
- A partir de ahí, entra en el bucle de juego, que sólo termina cuando el jugador humano teclea el comando especial “.Q”. Los comandos especiales empiezan siempre por punto (“.”).
- Es posible jugar varias partidas seguidas sin salir del programa.
Veamos cómo son la configuración inicial y el bucle de juego.
Configuración inicial:
La configuración inicial es la rutina “setup”, que ya está en el programa principal desde hace un par de versiones. La nueva rutina “setup” es así:

Es decir, la nueva rutina “setup”:
- Configura las tablas aleatorias con “fixedHash” (para depuración) o con “randomize” (para valores aleatorios).
- Inicializa la partida con la rutina “initBoard”.
- Con la rutina “gen”, genera los movimientos posibles desde la posición inicial. De este modo, se podrían mostrar con el comando especial “.M”.
- Mete el valor #PIECE_EMPTY en “computer_side”, de modo que el motor de juego no arranca automáticamente, sino que hay que arrancarlo manualmente con el comando especial “.G”.
- Inicializa “player”, porque de momento no se sabe quién va a jugar por cada bando, si el C64 o el humano.
- Fija el tiempo máximo por jugada en 5 minutos, aun cuando está función de jugar a tiempo fijo no está desarrollada del todo. Implicaría utilizar interrupciones del CIA1. Este tiempo se puede cambiar con el comando especial “.TM”, donde M es el número de minutos.
- Fija la profundidad de análisis a 4 niveles. Esta profundidad también se puede cambiar con el comando especial “.DN”, donde N es el nuevo nivel de profundidad.
Veamos ahora el bucle de juego.
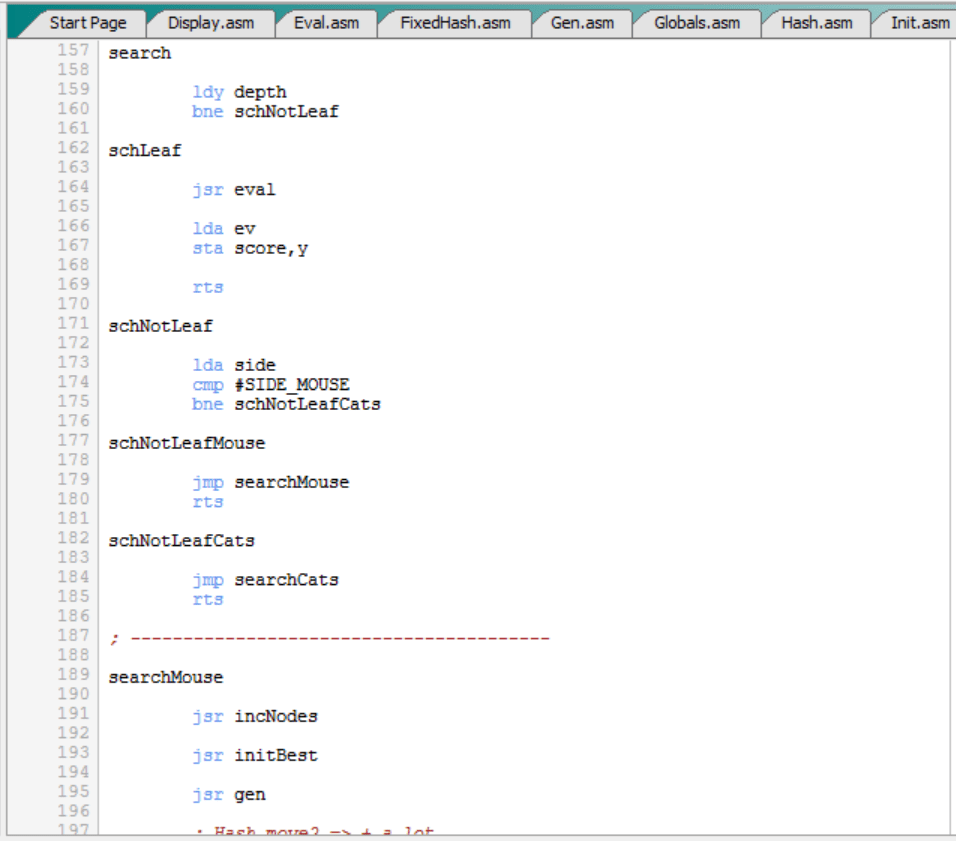
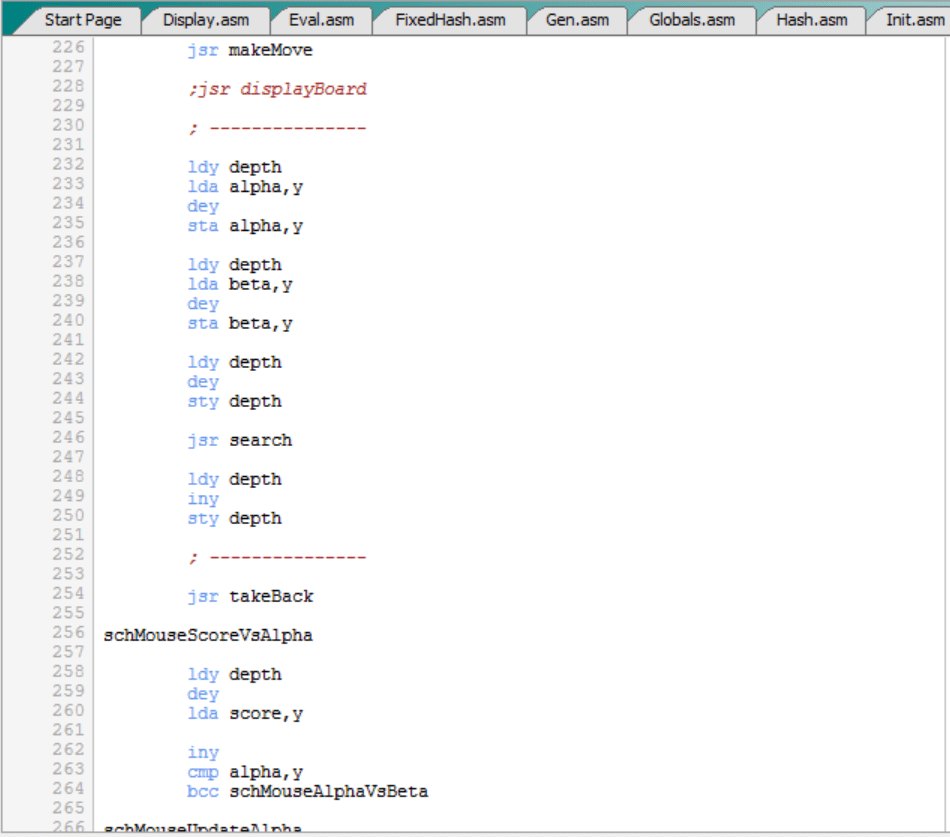
Bucle de juego:
El bucle de juego es esta parte específica del programa principal (inicialización con “setup” aparte):

Como se puede ver:
- Compara el bando al que le toca mover, que está en “side”, con el bando por el que juega el C64, que está en “computer_side”.
- Si son iguales, es decir, si le toca mover al ratón y el C64 juega por el ratón, o si le toca mover a los gatos y el C64 juega por los gatos, entonces ejecuta “computerTurn”. Como veremos más adelante, “computerTurn” básicamente ejecuta la profundización iterativa, es decir, “thinkIter”.
- Por el contrario, si son distintos, es decir, si le toca mover al ratón y el C64 juega por los gatos, o al revés, entonces ejecuta “humanTurn”. Esto permite que el jugador humano mueva o ejecute un “comando especial”.
- El punto anterior tiene un caso especial, que es cuando “computer_side” vale #PIECE_EMPTY, que es su valor inicial. Esto significa que el C64 de momento está parado, que no juega ni por el ratón ni los gatos. En este caso, es imposible que “side” y “computer_side” sean iguales, puesto que “side” sólo puede valer ratón o gatos, así que en este caso siempre se ejecuta “humanTurn”. Es decir, cuando el motor está parado sólo puede mover o ejecutar comandos el humano. Todo ello hasta que se arranque el motor con el comando “.G”, que básicamente lo que hace es darle un valor a “computer_side”.
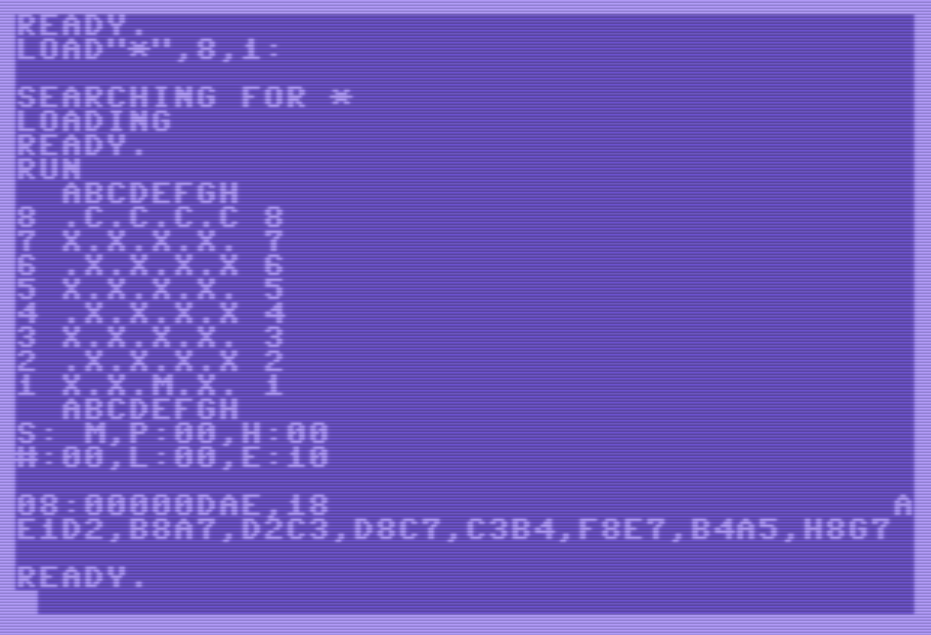
Gracias a este bucle de juego tan flexible es posible arrancar el juego con “RUN”, que ejecuta el cargador BASIC “10 SYS 2080”, y hacer cosas como:
- Mostrar el tablero con “.B”:

- Mover por el ratón con “E1F2”:

- Volver a mostrar el tablero con “.B”:

- Pedirle al C64 que mueva por los gatos con “.G”:
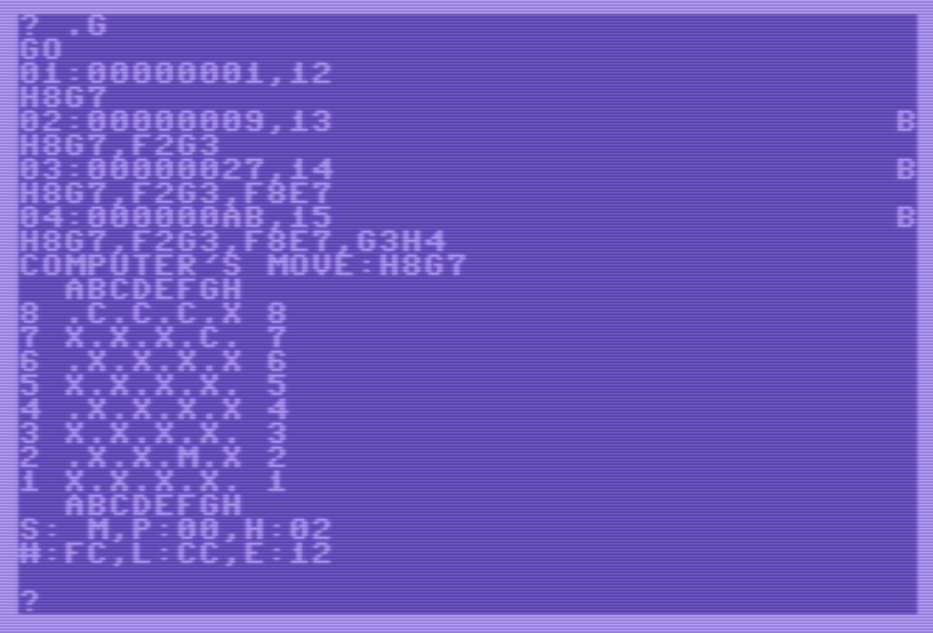
- Volver a pedirle al C64 que mueva, ahora por el ratón, con “.G”:
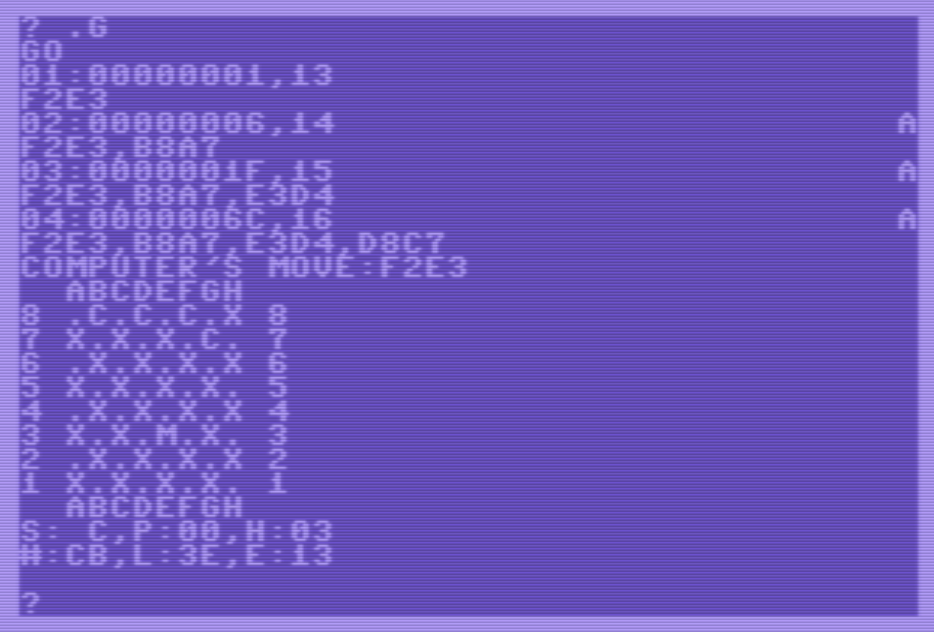
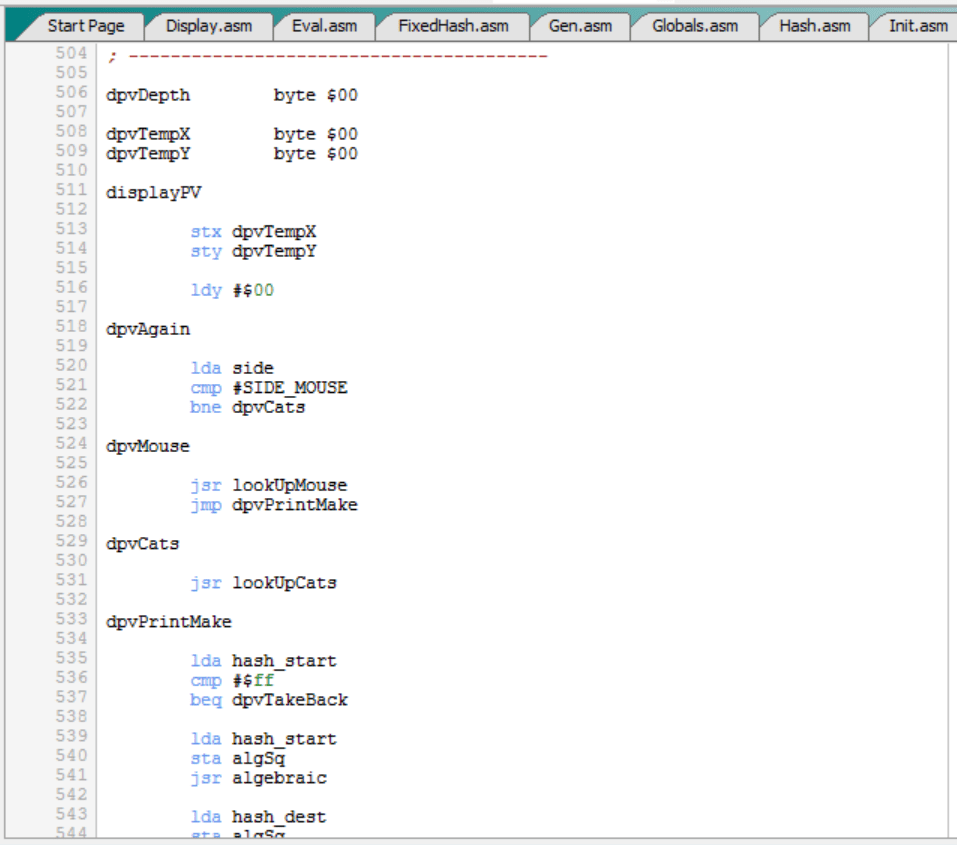
- Pedir los movimientos posibles con “.M”:
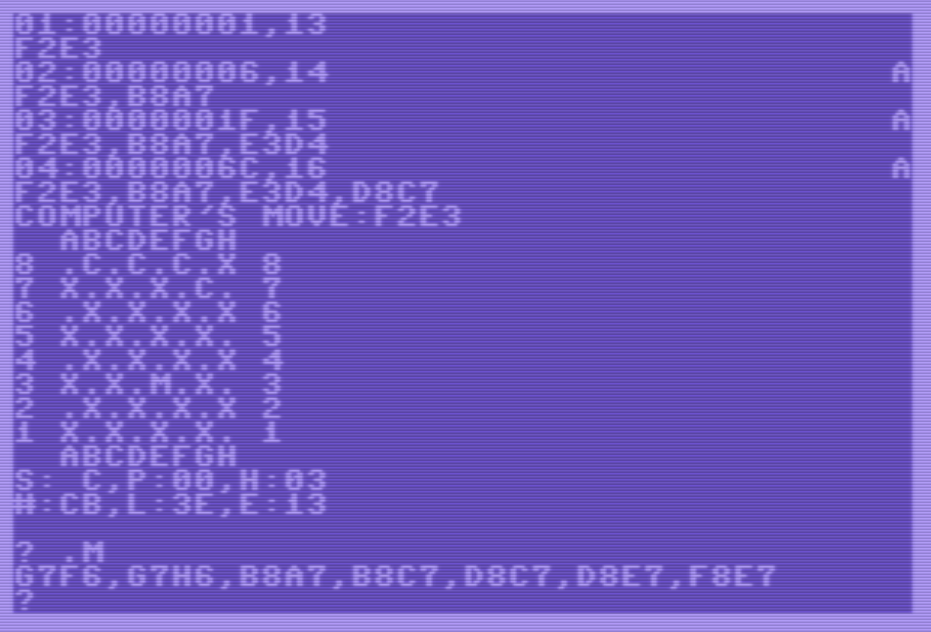
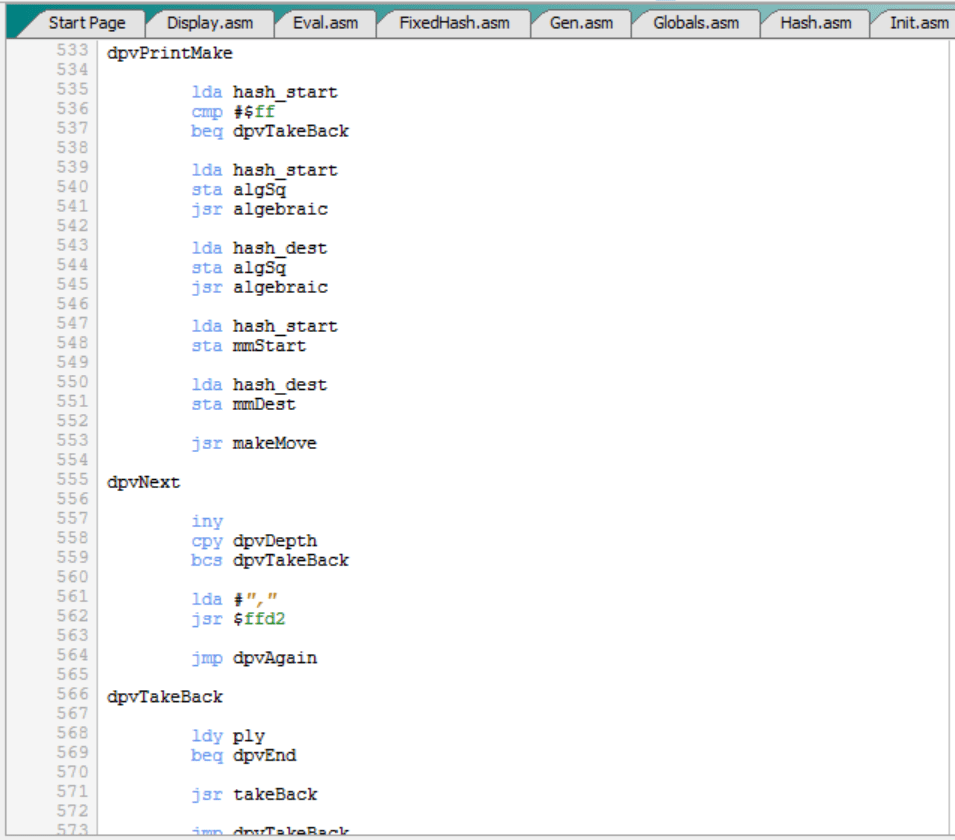
- Mover ahora por los gatos con “F8E7”. Como el motor está arrancado, el C64 vuelve a mover automáticamente por el ratón con “E3D4”:

- Parar el motor con “.O”:

- Volver a pedir los movimientos posibles con “.M”.
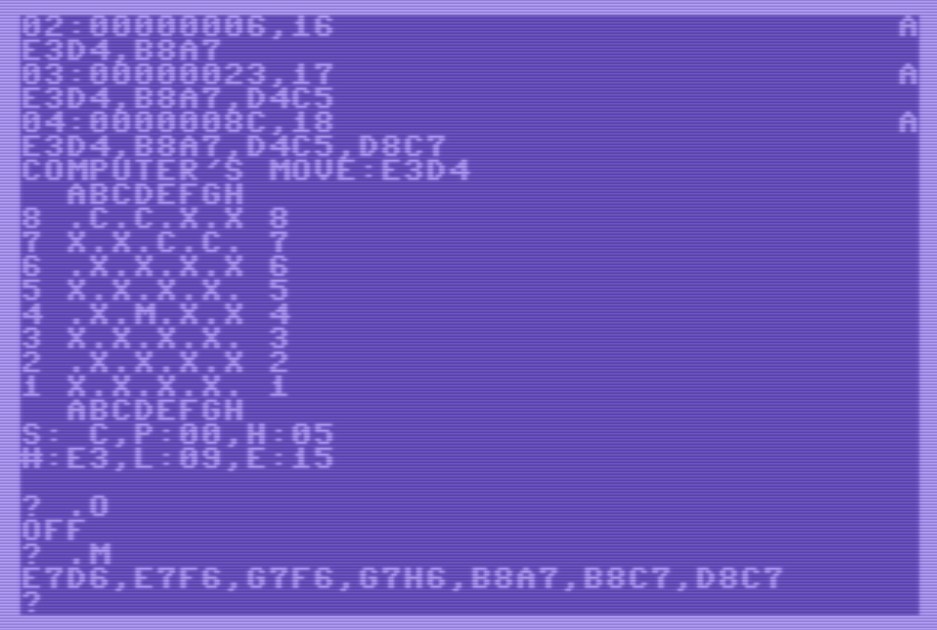
- Volver a mover por los gatos con “D8C7”. Como el motor ahora está parado, el C64 no mueve automáticamente por el ratón:
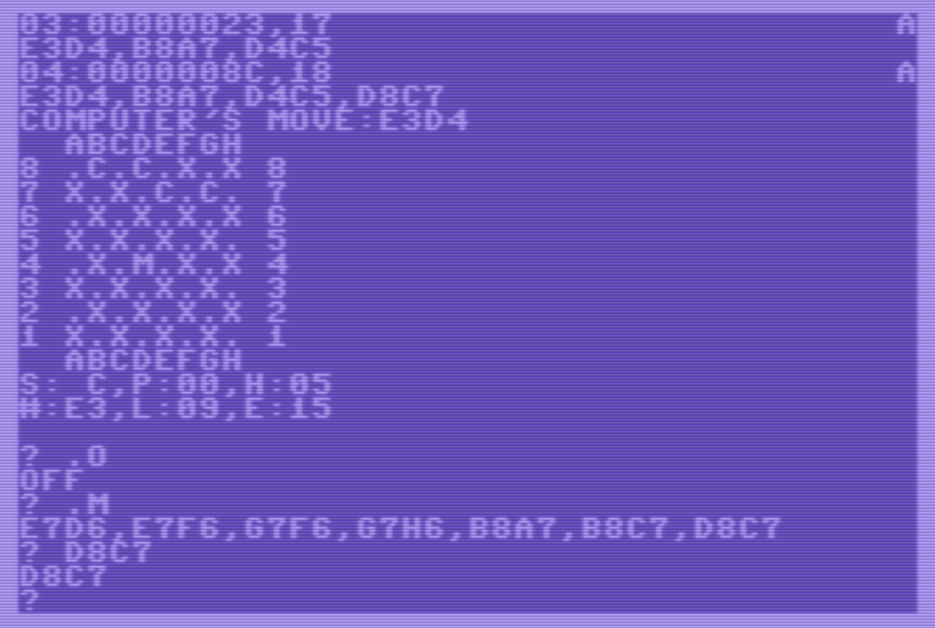
- Volver a mostrar el tablero con “.B”:

- Salir del juego con “.Q”:

Lógicamente, lo normal será que el C64 juegue por un bando y el humano por otro, pero un bucle de juego como éste permite todo tipo de opciones y cambios.
C´´odigo del proyecto: RYG3-09