En la entrada anterior ya vimos qué es el lock: un segundo hash que complementa al hash original de un tablero, y que sirve para reducir la probabilidad de que dos tableros distintos tengan el mismo hash (y lock), de modo que se puedan evitar errores en el uso de las tablas hash como consecuencia de las colisiones.
Vamos a ver cómo introducir el lock en el programa:
Tablas con valores aleatorios para el lock:
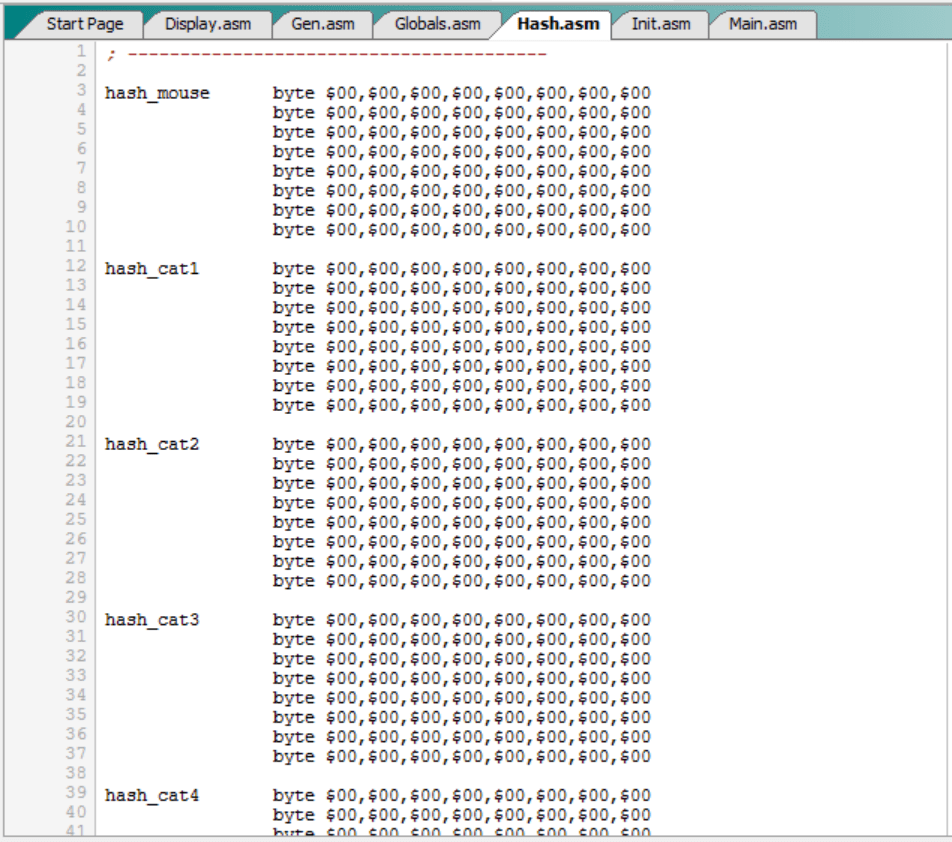
El programa original utilizaba las tablas “hash_mouse” y “hash_catN” para almacenar unos valores aleatorios generados a partir del SID y luego utilizar esos valores aleatorios para generar el hash de un tablero.
Pues bien, el programa mejorado tendrá unas nuevas tablas “lock_mouse” y “lock_catN” totalmente equivalentes:
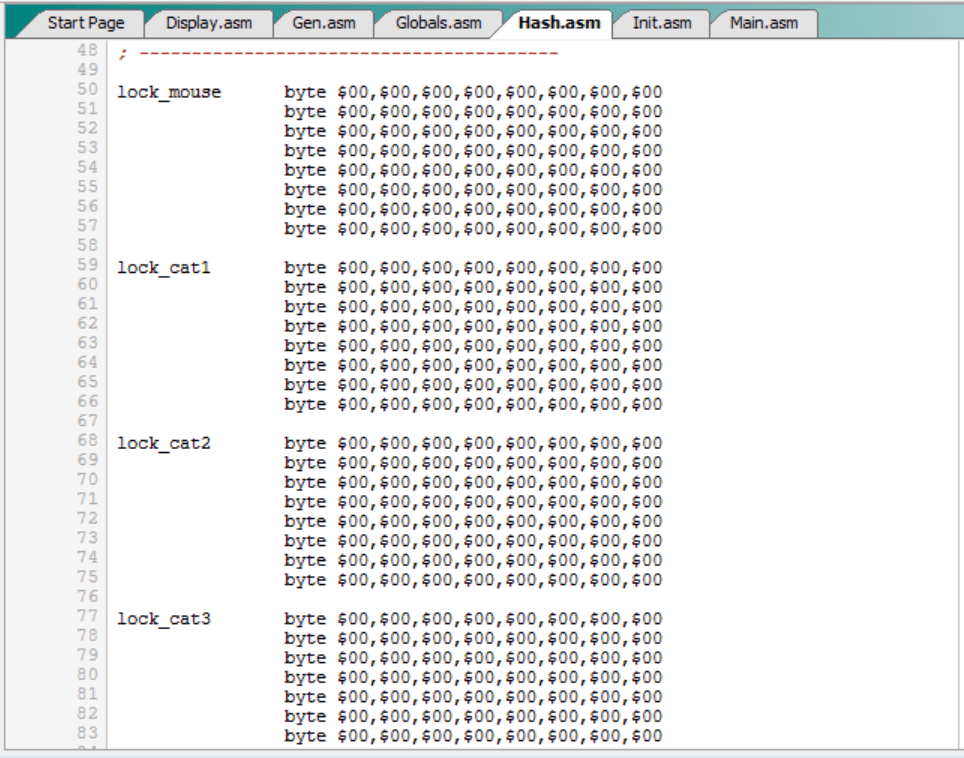
Estas nuevas tablas se rellenarán con valores aleatorios mediante una nueva versión de la rutina “randomize”.
Nueva rutina “randomize”:
La versión original de la rutina “randomize”:
- Inicializaba la frecuencia de la tercera voz del SID ($ffff).
- Configuraba la forma de onda a “ruido” y activaba la tercera voz.
- Leía un primer valor aleatorio de la tercera voz (“seed”).
- Inicializaba las tablas “hash_mouse” y “hash_catN” con valores aleatorios, usando para ello las rutinas auxiliares “randHash*”.
Pues bien, la nueva rutina “randomize” hace todo lo anterior y, además, inicializa las tablas “lock_mouse” y “lock_catN” con valores aleatorios mediante el uso de unas nuevas rutinas auxiliares “randLock*”:
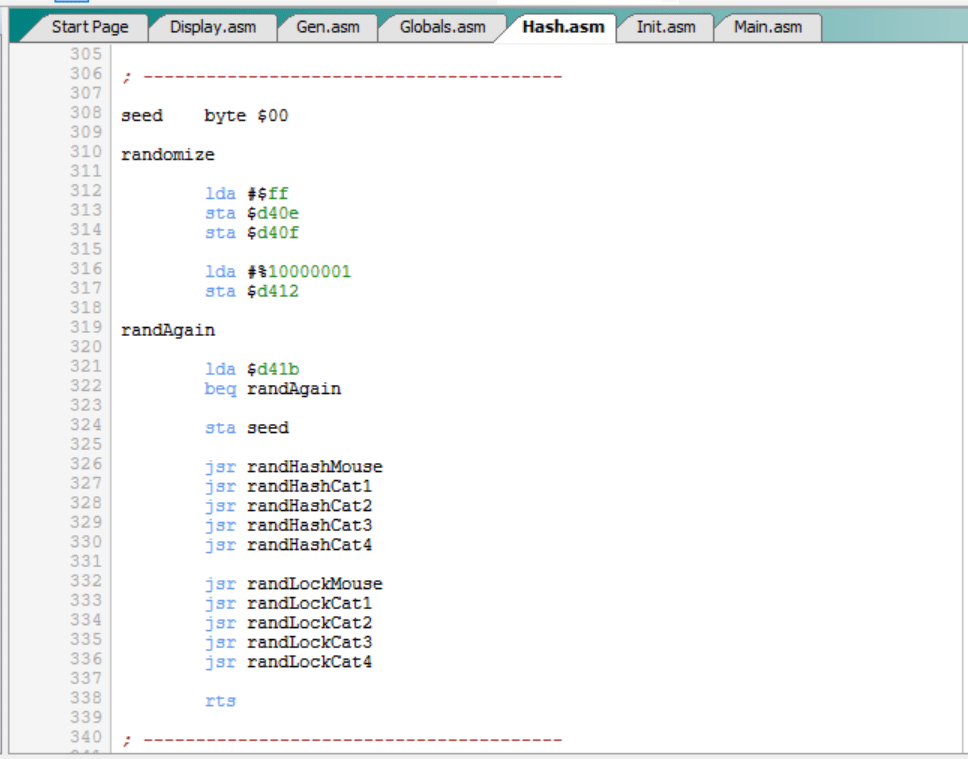
Las nuevas rutinas auxiliares “randLock*” son totalmente equivalentes a las rutinas “randHash*” anteriores.
Generación del lock de un tablero:
Igual que en el programa original había que generar el hash de un tablero, para lo cual se utilizaba la rutina “getHash”, ahora hay que generar el lock de un tablero, para lo cual se utiliza una nueva rutina “getLock”:

La nueva rutina “getLock” es totalmente equivalente a “getHash”, es decir, inicializa el lock a cero y recorre el tablero localizando piezas (ratón o gatos), en función de las cuales consulta las posiciones análogas de las tablas aleatorias (“lock_mouse” y “lock_catN”), haciendo el OR exclusivo (“eor”) de esos valores. El resultado es el lock del tablero.
Nuevas tablas “hashpos_mouse” y “hashpos_cats” con lock:
Los tableros ya tienen un hash y un lock (un segundo hash). Ahora vamos a ver qué hacemos con ellos, especialmente con el lock:
Una primera opción sería que las tablas hash “hashpos_mouse” y “hashpos_cats”, que recordemos que sirven para almacenar el mejor movimiento asociado a un tablero, fueran tablas de doble entrada. Es decir, en vez de usar como índice el hash, podríamos usar como índices el hash y el lock. De este modo, como es muy improbable que dos tableros distintos tengan el mismo hash y el mismo lock, es muy improbable que se dé una colisión.
Ahora bien, el hash ocupa un byte (256 posibles valores) y el lock también. Eso significa que una tabla de doble entrada hash x lock tendría 256 x 256 posiciones, es decir, 65.536 posiciones o, lo que es lo mismo, toda la RAM del C64. Por tanto, este enfoque no es viable.
Una segunda opción consiste en que las tablas hash “hashpos_mouse” y “hashpos_cats” sigan siendo tablas unidimensionales (índice = hash) pero, además de un movimiento (origen, destino), también almacenen el lock del tablero asociado:
- “hashpos_mouse_start”, “hashpos_mouse_dest” y “hashpos_mouse
_lock”. - “hashpos_cats_start”, “hashpos_cats_dest” y “hashpos_cats
_lock”.

De este modo, sigue siendo posible que dos tableros distintos tengan el mismo hash, y sigue siendo posible que el segundo movimiento que se almacene en la tabla hash “machaque” el primero (colisión), pero, tras consultar el mejor movimiento asociado a un tablero, y mediante la verificación del lock almacenado, podemos saber si ese “mejor movimiento” efectivamente proviene del tablero actual o de otro tablero con el mismo hash. Es decir, podemos saber si proviene de una colisión o no y, en caso afirmativo, al menos podemos evitar usar ese movimiento.
Es decir, con el lock no eliminamos las colisiones, ni tampoco reducimos su probabilidad, para ser sinceros, pero al menos las detectamos y evitamos usar información incorrecta.
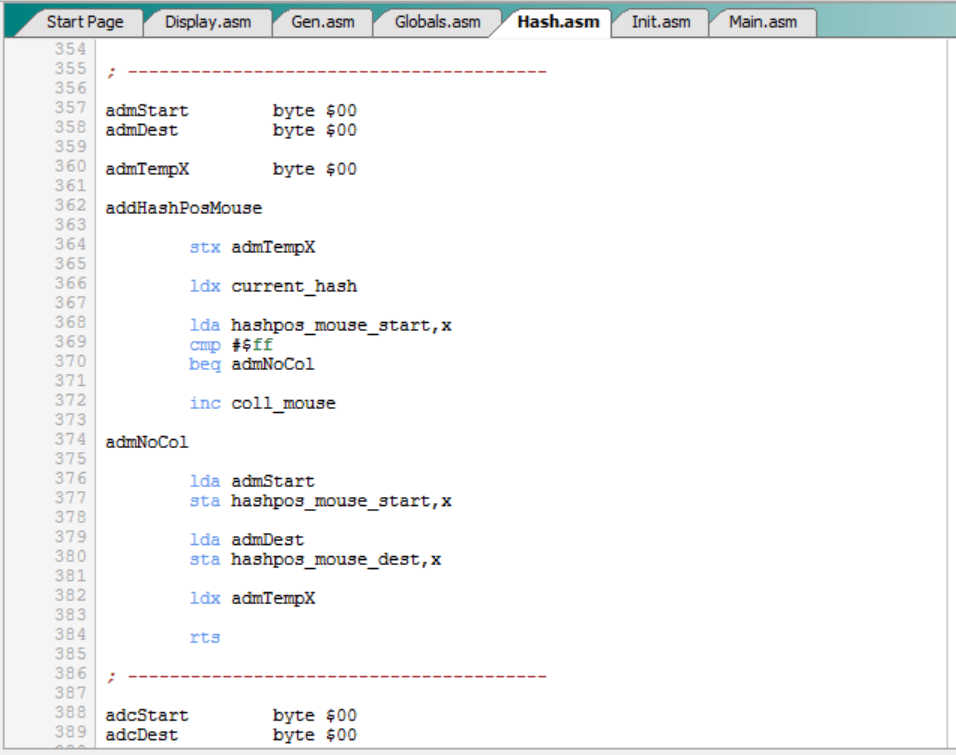
Nuevas rutinas “addHashPosMouse” y “addHashPosCats”:
Las rutinas “addHashPosMouse” y “addHashPosCats” sirven para almacenar en la tabla hash el mejor movimiento asociado a un tablero, en función de que sea el turno del ratón o los gatos, respectivamente.
Ahora, dado que las tablas hash van a tener un movimiento (origen, destino) y un lock, hay que mejorar estas rutinas para almacenar el lock. En el caso de la rutina “addHashPosMouse” queda así:

La rutina “addHasPosCats” es totalmente equivalente.
Nuevas rutinas “lookUpMouse” y “lookUpCats”:
Las rutinas “lookUpMouse” y “lookUpCats” sirven para consultar en las tablas hash el mejor movimiento asociado a un tablero. Anteriormente, había dos opciones:
- La posición de la tabla hash correspondiente al hash del tablero estaba vacía (valor = $ff). En ese caso se devolvía una señal.
- La posición de la tabla hash correspondiente al hash del tablero tenía un movimiento (valor <> $ff). En ese caso se devolvía el movimiento (start, dest) en (hash_start, hash_dest).
Pues bien, ahora hay una opción intermedia, consistente en que la posición de la tabla hash no está vacía (valor <> $ff), sino que tiene un movimiento, pero tiene un lock diferente al del tablero actual. Es decir, se trata de una colisión. En este caso, se devuelve una señal igual que en el caso vacío, que puede ser exactamente la misma señal o una diferente, si se quieren distinguir las situaciones:
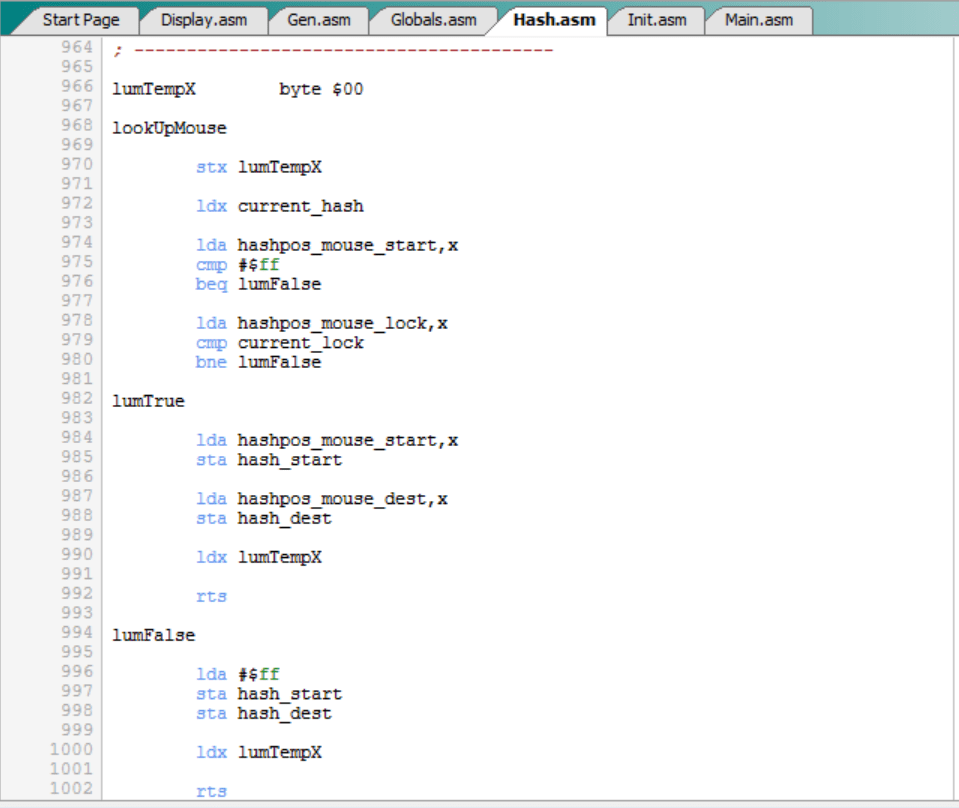
Nótese la instrucción “bne lumFalse” de la línea 980 de “Hash.asm”. En esa línea se está detectando la colisión al consultar el mejor movimiento asociado al tablero.
Nuevo programa principal:
Por último, hacemos un nuevo programa principal para probar el lock. El nuevo programa principal es muy parecido al anterior:

Es decir:
- Inicializa e imprime el tablero.
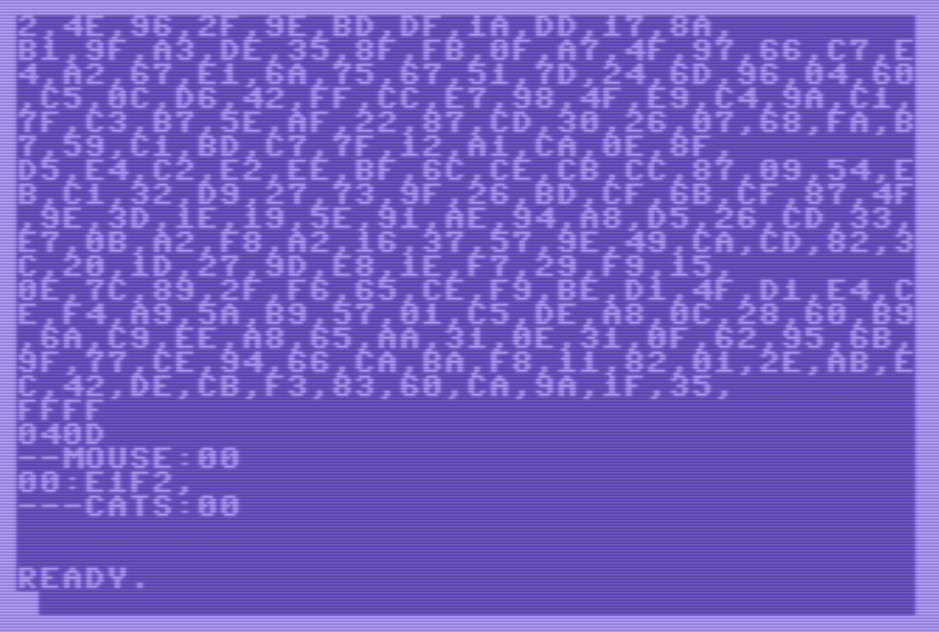
- Llama a la rutina “testRandomizeLocks”. Esta rutina imprime el contenido inicial de las tablas aleatorias del lock, luego las inicializa con valores aleatorios, y luego las vuelve a imprimir.
- Llama a la rutina “testAddHashAndLookUp”. Esta rutina consulta el movimiento asociado a un tablero en la tabla hash del ratón (inicialmente no existe), luego inserta el movimiento 4 => 13 (E1 => F2), ya con el lock, y luego vuelve a consultar el movimiento.
- Llama a la rutina “testHashPositions”, que pinta el contenido de las tablas hash de ratón y gatos.
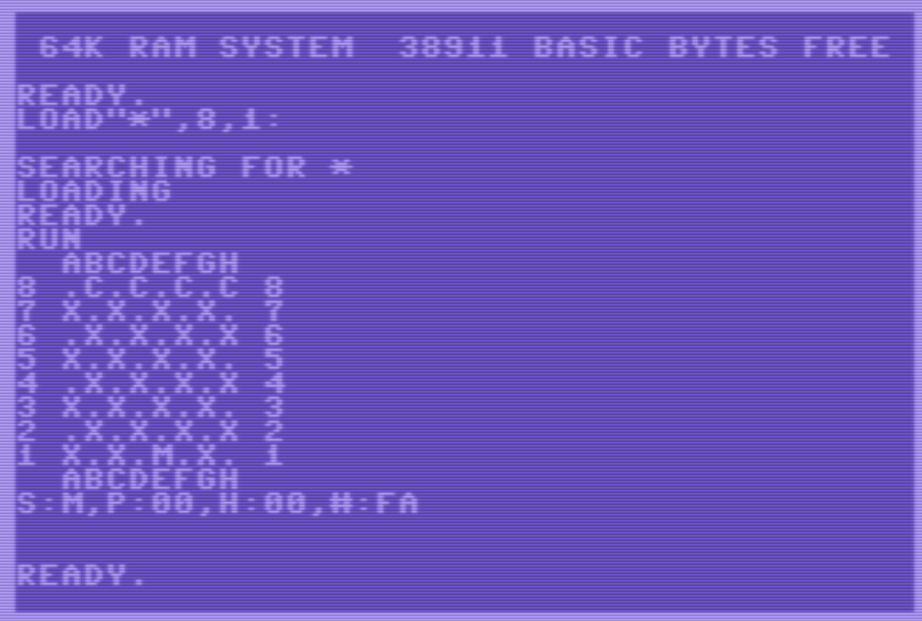
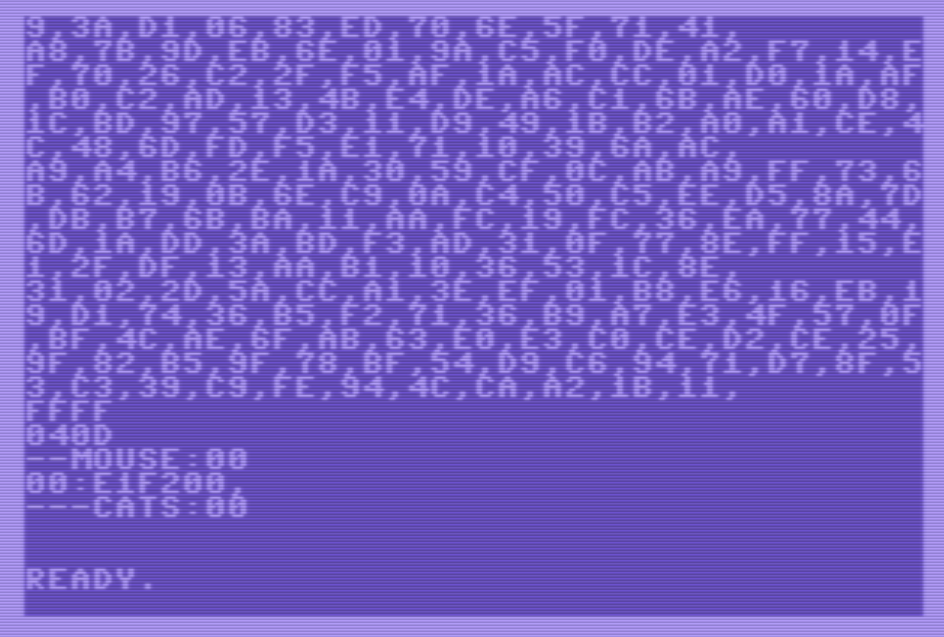
De este modo, el resultado de la ejecución es así (el “00” que se ve a la derecha del movimiento “E1F2” es el lock almacenado en la tabla hash):
Código del proyecto: RYG3-04