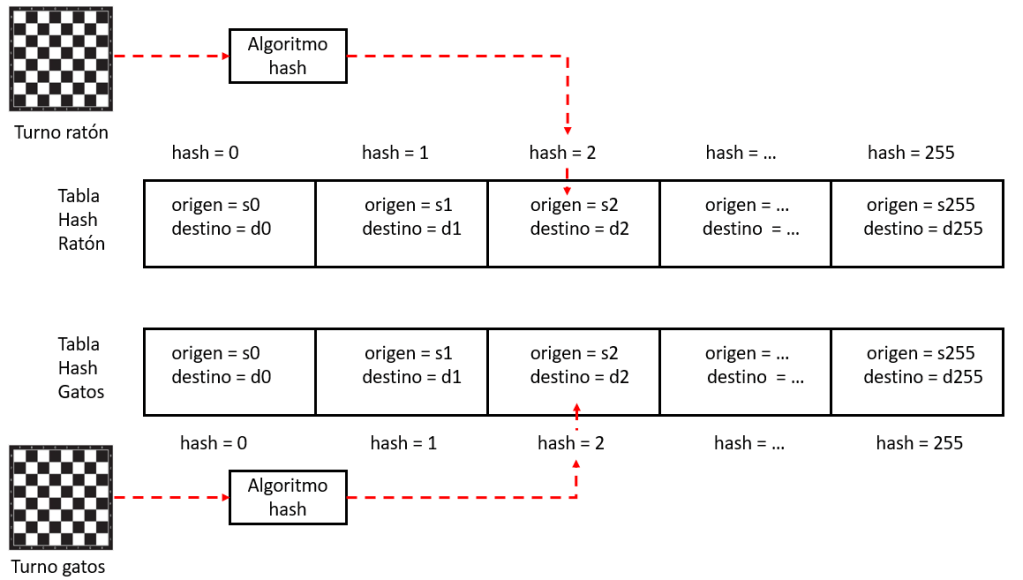
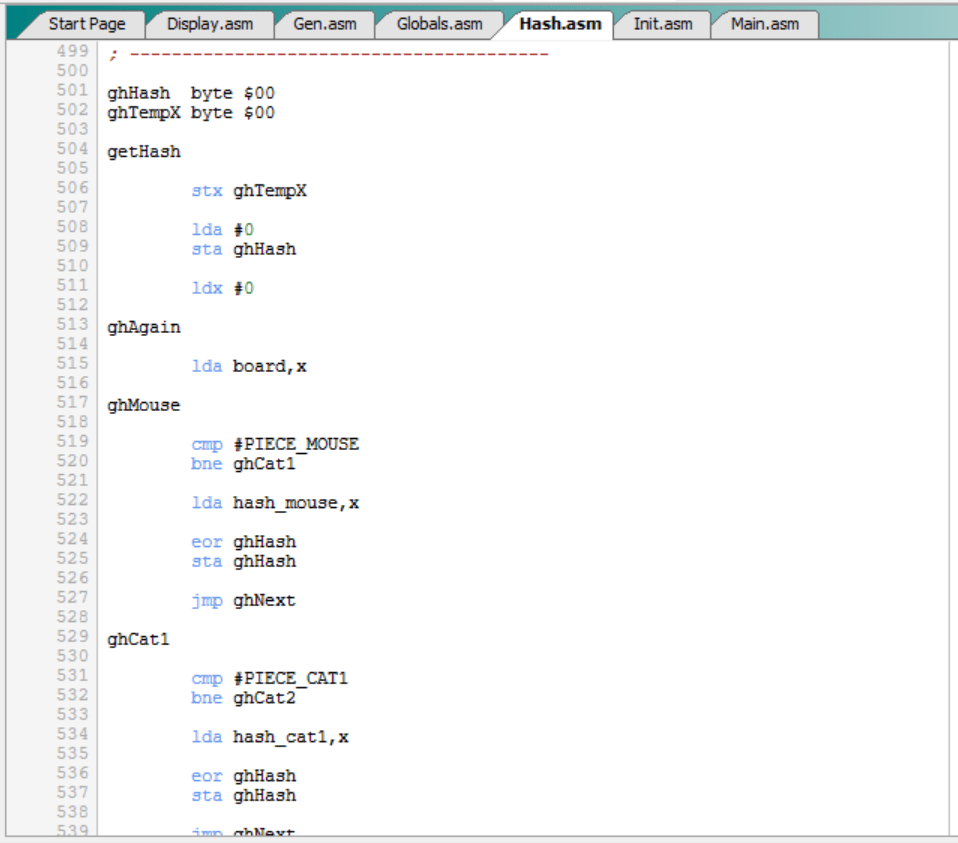
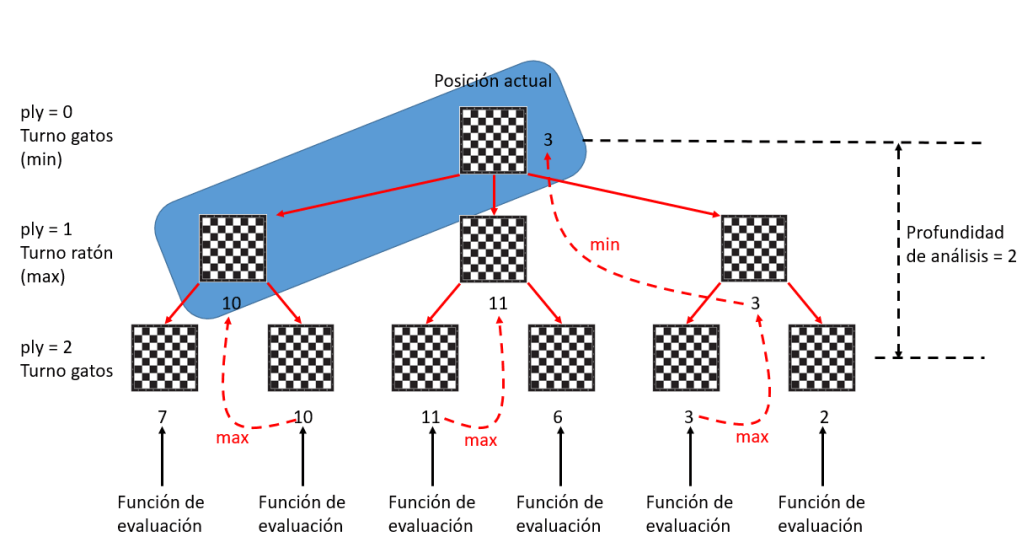
Es improbable que dos tableros distintos, es decir, con el ratón y/o los gatos en posiciones distintas, den lugar al mismo hash. Es improbable porque, en función de las piezas y sus posiciones, se consultan unas posiciones u otras de las tablas generadas aleatoriamente (“hash_*”) y, por tanto, se utilizan números diferentes para el OR exclusivo. Sin embargo, aunque improbable, no es imposible.
Esto es lo que se llama una “colisión”. Si dos tableros distintos dan lugar al mismo hash, a la hora de insertar el mejor movimiento asociado en la tabla hash (“hashpos_*”), se producirá una colisión, puesto que ambos movimientos se almacenarán en la misma posición de la tabla hash. El que se almacene en segundo lugar “machacará” al que se haya almacenado en primer lugar.
Lógicamente, que haya colisiones no es bueno para el funcionamiento del programa. Las tablas hash valen para almacenar y consultar el mejor movimiento asociado a un tablero. Por tanto, si se producen colisiones esa información se pierde para algunos tableros al sustituirse por la de otros tableros que tienen el mismo hash. Peor que perderse, se sustituye por otra información posterior. Es decir, el programa puede tomar decisiones incorrectas sobre los movimientos a realizar.
Hay técnicas para resolver las colisiones, como se puede ver en https://es.wikipedia.org/wiki/Tabla_hash#Resoluci%C3%B3n_de_colisiones. Y también hay técnicas para reducir la probabilidad de que ocurran sin llegar a reducirla a cero.
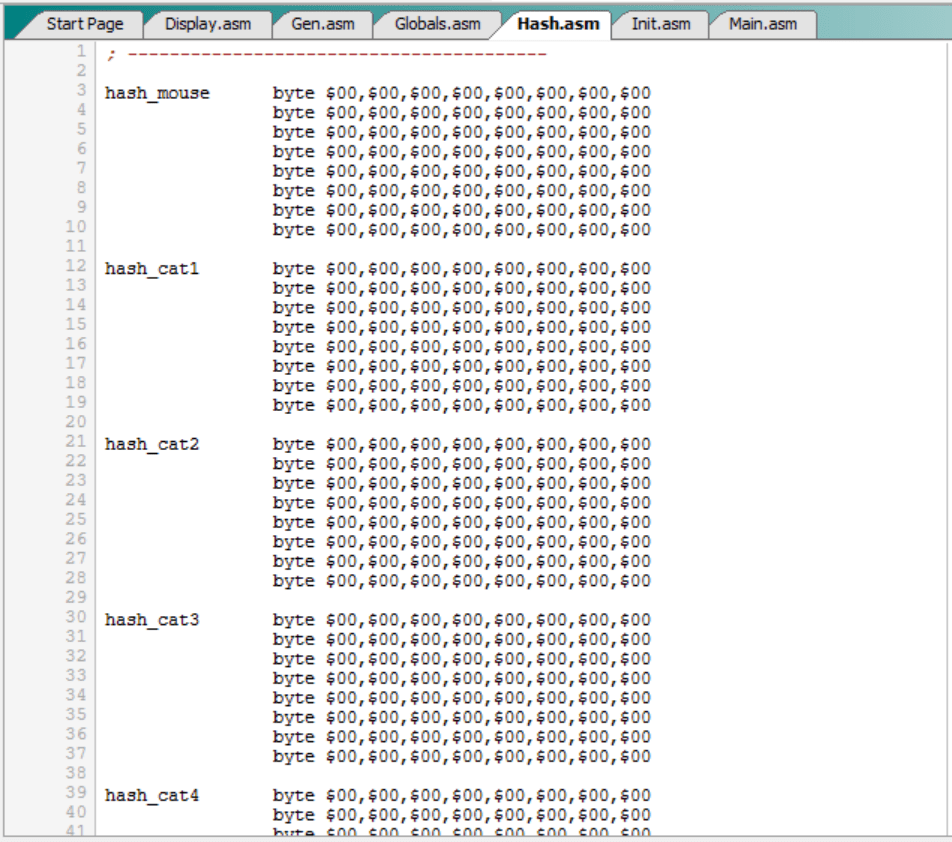
Una primera técnica consiste en que las tablas hash sean muy grandes o, lo que es lo mismo, que haya muchos hashes posibles. En nuestro caso, dado que el hash ocupa un byte sólo hay 256 valores posibles y las tablas hash (“hashpos_*”) tienen 256 posiciones. Pero se podrían usar 9 bits para el hash, en vez de 8, en cuyo caso habría 512 hashes posibles y dos tablas hash de 512 posiciones.
Y otra técnica es complementar el hash con un “lock”, que no deja de ser lo mismo, es decir, un segundo hash, pero elaborado a partir de otras tablas aleatorias. De este modo, todo tablero tiene dos hashes (un hash y un lock) y, ahora ya sí, la probabilidad de que dos tableros distintos tengan el mismo hash y el mismo lock ya es prácticamente cero.
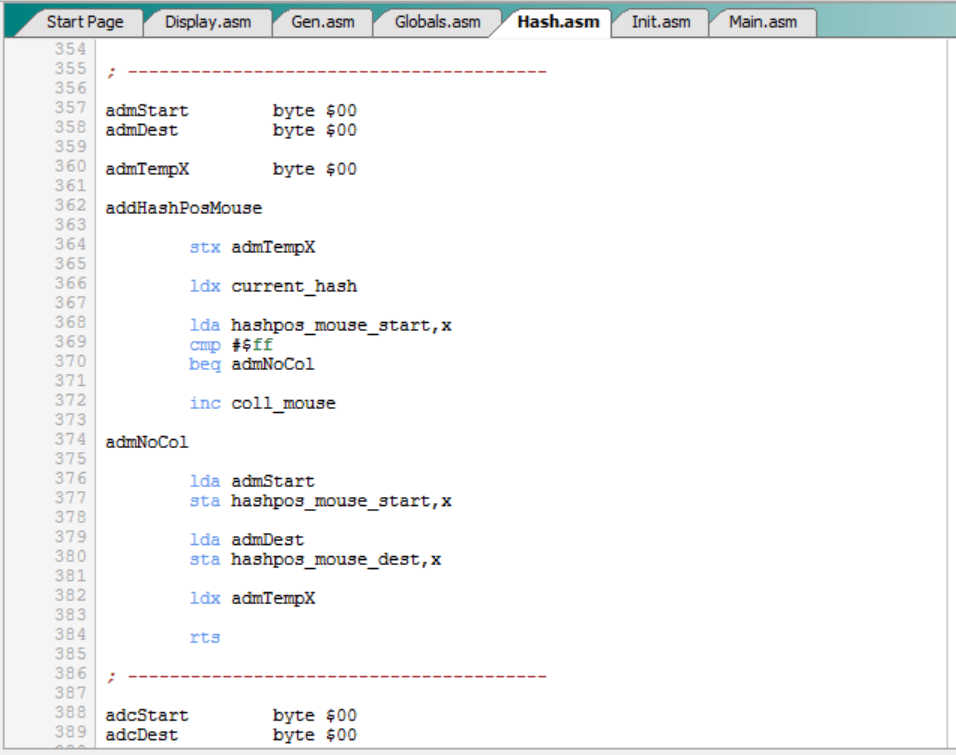
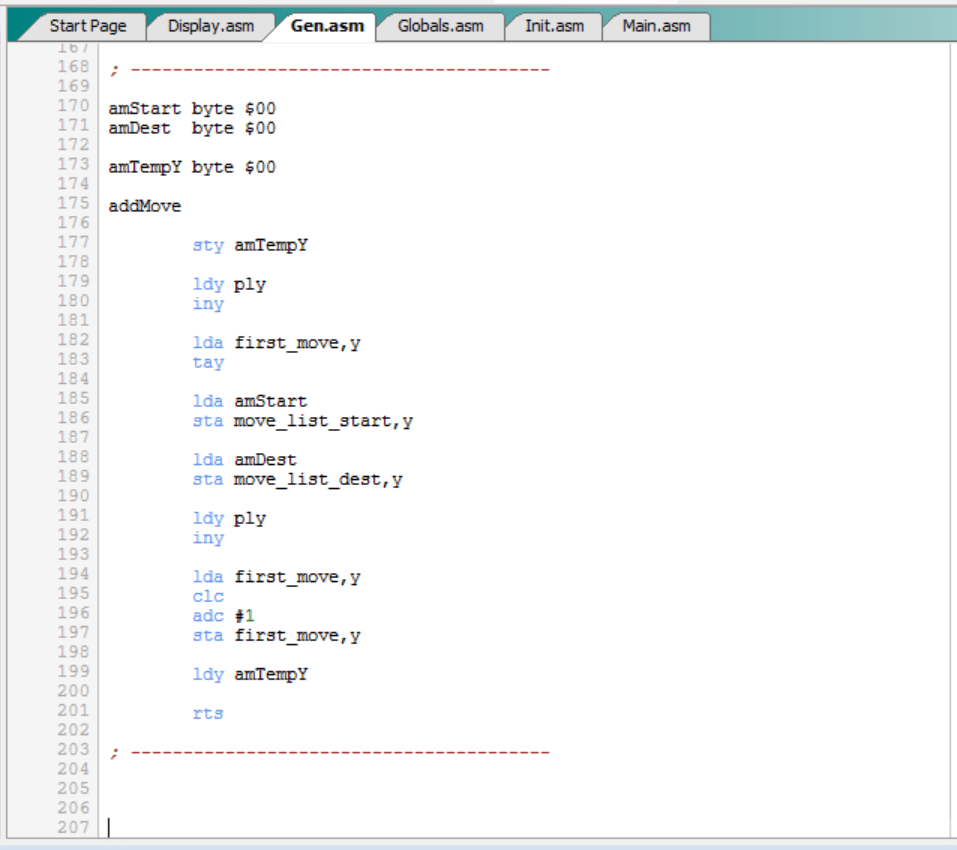
El uso de tablas hash con lock se describirá en la entrada siguiente. De momento, baste recordar que cuando las rutinas “addHashPosMouse” y “addHashPosCats” insertan un movimiento (origen, destino) en las tablas “hashpos_mouse” o “hashpos_cats” respectivamente, y la posición del hash ya está ocupada (valor distinto del valor inicial $ff), se detecta una colisión y se incrementa el contador “coll_mouse” o “coll_cats”, lo que al menos servirá para saber si tenemos muchas o pocas colisiones.