
La búsqueda alfa – beta, es decir, con poda, la vamos a implementar en la rutina “search” del nuevo fichero “Search.asm”.
De primeras, parece que lo más lógico sería que, si se quiere una profundidad de análisis de ocho niveles, por decir algo, se desarrolle directamente un árbol de juego de profundidad ocho. Esto es lo que llamamos “búsqueda a máxima profundidad”.
Sin embargo, en la práctica no suele ser así. La poda alfa – beta es más o menos eficiente podando en función de cómo se ordenen las jugadas o, lo que es lo mismo, dependiendo de cómo se ordenen los tableros hijo de un tablero dado. Si las mejores jugadas se analizan o desarrollan antes, se poda más y mejor.
Por ello, cualquier enfoque para desarrollar el árbol que no genere las jugadas en un orden arbitrario, sino que favorezca una ordenación lógica de las mismas, adelantando el desarrollo de las mejores jugadas y posponiendo el de las peores, tendrá un efecto favorable en la poda.
En esta entrada vamos a ver la “búsqueda a máxima profundidad”. En la entrada siguiente veremos la “profundización iterativa” (“iterative deepening” en inglés), que es una alternativa para mejorar la ordenación de jugadas y la poda.
Nueva rutina “search”:
La rutina “search” se define en el nuevo fichero “Search.asm”. Su definición es así:
Es decir, recibe:
- La profundidad de análisis “depth”.
- Los parámetros “alpha” y “beta” de la poda alfa – beta.
Y devuelve:
- La puntuación “score”.
- Y el mejor movimiento encontrado (“best_start”, “best_dest”).
Y para hacer lo anterior necesita:
- Saber por qué movimiento va de todos los posibles con “current_move”.
- Y cuál es el último movimiento de todos los posibles con “last_move”.
Quitando “depth”, que es una posición de memoria simple (un byte), el resto de parámetros son tablas de N posiciones a las que accederemos usando “depth” como índice. Esto es necesario porque “search” es una rutina recursiva, es decir, se llama a sí misma, y no debemos perder la cuenta de los sucesivos valores de llamada y retorno.
Y lo primero que hace la rutina “search” es esto:
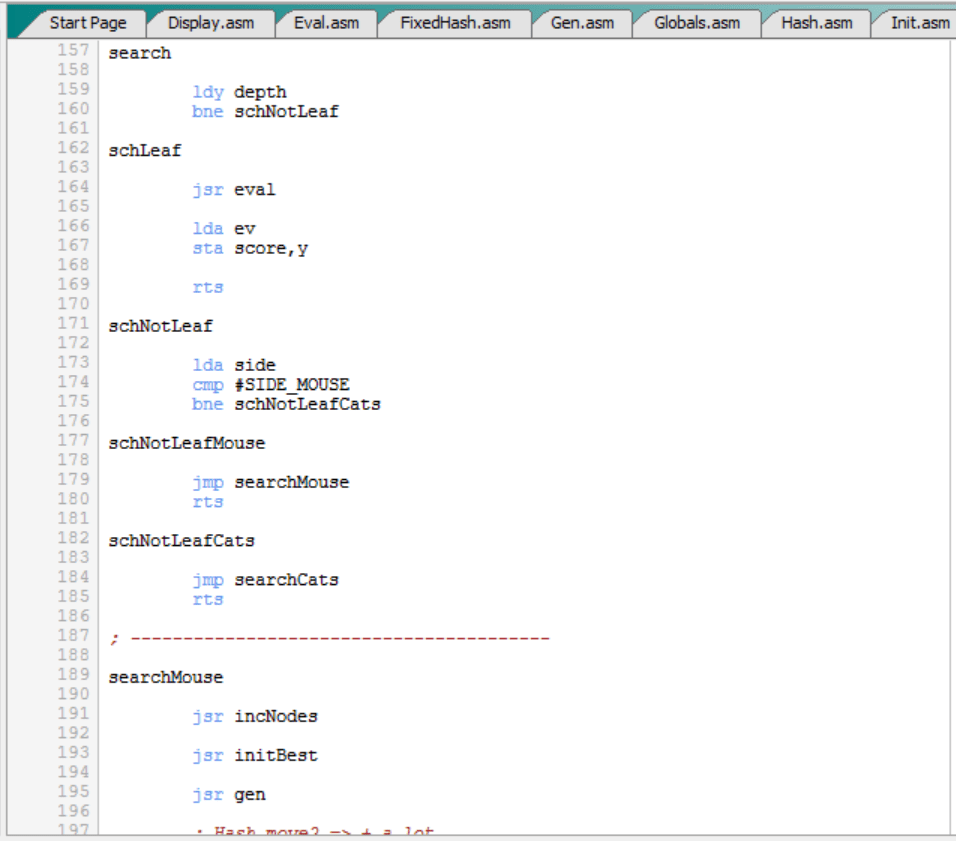
Es decir:
- Carga la profundidad “depth” en el índice Y.
- Si “depth” es cero ya estamos en el final del árbol, es decir, en las hojas y, por tanto, llamamos a la función de evaluación “eval” y el valor de la evaluación “ev” lo devuelve en “score” (indexado por Y).
- Si “depth” no es cero todavía estamos en un nodo intermedio y, por tanto, llama a “searchMouse” o “searchCats” en función del turno “side”.
Las subrutinas “searchMouse” y “searchCats” son totalmente equivalentes. Lo único que cambia es el bando. La primera es para el ratón, es decir, el jugador maximizador, y la segunda es para los ratones, es decir, el jugador minimizador. Con analizar una de ellas es suficiente, porque la otra es totalmente análoga.
Subrutina “searchMouse”:
Como hemos dicho, las subrutinas “searchMouse” y “searchCats” son totalmente equivalentes. Por tanto, llegará con analizar en detalle la primera.
Lo primero que hace “searchMouse” es así:

Es decir:
- Incrementa el número de nodos desarrollados llamando a “incNodes”. Esta rutina simplemente incrementa en uno el número de nodos analizados (4 bytes) almacenado en las posiciones nodes4 – nodes3 – nodes2 – nodes1.
- Inicializa la mejor jugada llamando a “initBest”. Esta rutina simplemente inicializa a ($ff, $ff) el mejor movimiento encontrado (“best_start”, “best_dest”). Lógicamente, $ff es un valor de casilla inválido.
- Genera la lista de movimientos posibles llamando a “gen”. Recordemos que “gen” almacena los movimientos posibles en la tabla “move_list”, y que la tabla asociada “first_move” nos da punteros para acceder a los movimientos de “move_list” en función del número de jugada “ply”.
Con los movimientos posibles generados con “gen”, “searchMouse” sigue así:
- Usando “ply” como índice y “first_move”, toma la posición que ocupa el primer movimiento de “move_list”. Esta posición la guarda en “current_move”, que se irá actualizando según se vayan probando movimientos.
- Usando “ply+1” como índice y “first_move”, toma la posición que ocupa el último movimiento de “move_list”. Esta posición la guarda en “last_move”, que será el tope contra el que comprobar “current_move” para saber si hemos probado todos los movimientos.
Y ahora “searchMouse” sigue así:

Es decir:
- Usando “current_move” tenemos la posición que ocupa el movimiento a probar en “move_list”.
- Leemos de “move_list” ese movimiento, es decir, (“move_list_start”, “move_list_dest”).
- Y probamos ese movimiento con “makeMove”. Decimos “probar” porque a estas alturas para nada está decidido que ese sea el movimiento finalmente elegido. De momento sólo se trata de ir desarrollando el árbol, ir aplicando la búsqueda alfa – beta, y encontrar el mejor movimiento de todo el proceso, que será el que finalmente se aplique.
Una vez probado el movimiento con “makeMove” habrá que deshacerlo con “takeBack”, puesto que de momento no es un movimiento definitivo, sino una prueba para saber cómo de bueno o malo es. Y después de deshacerlo con “takeBack” usaremos su puntuación “score” para compararlo con “alpha”, puesto que estamos analizando “searchMouse”, y el ratón es el jugador maximizador.
Pero antes de seguir con todo esto, tenemos que desarrollar el árbol “en profundidad”. Es decir, tenemos que llamar recursivamente a “search”. Esto se hace aquí:
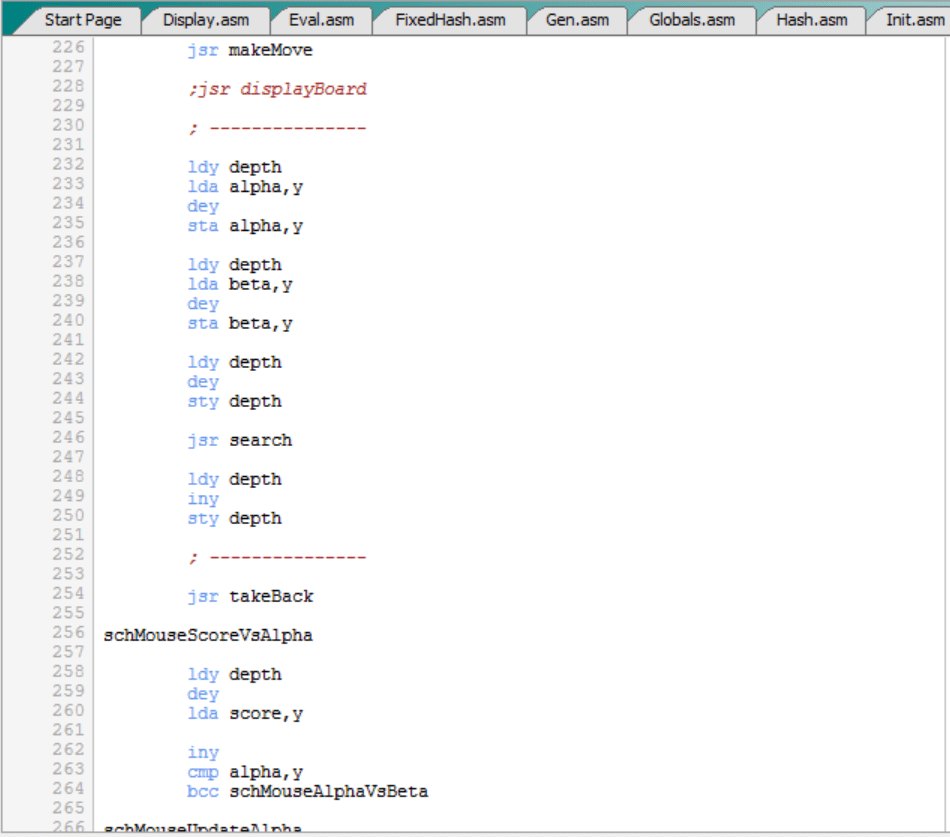
Es decir:
- El valor de “alpha” al nivel “depth” lo pasamos como “alpha” del nivel “depth-1”.
- El valor de “beta” al nivel “depth” lo pasamos como “beta” del nivel “depth-1”.
- Decrementamos “depth” en 1, puesto que nos estamos acercando un nivel al extremo del árbol, a las hojas.
- Llamamos recursivamente a “search”.
A la vuelta, es decir, al terminar “search”, lo primero que hacemos es incrementar “depth” en 1 para dejarlo en el valor que estaba y continuar con la búsqueda en ese nivel.
Ahora ya sí, tras volver de la llamada recursiva a “search” y devolver “depth”a su valor, “searchMouse” continúa:
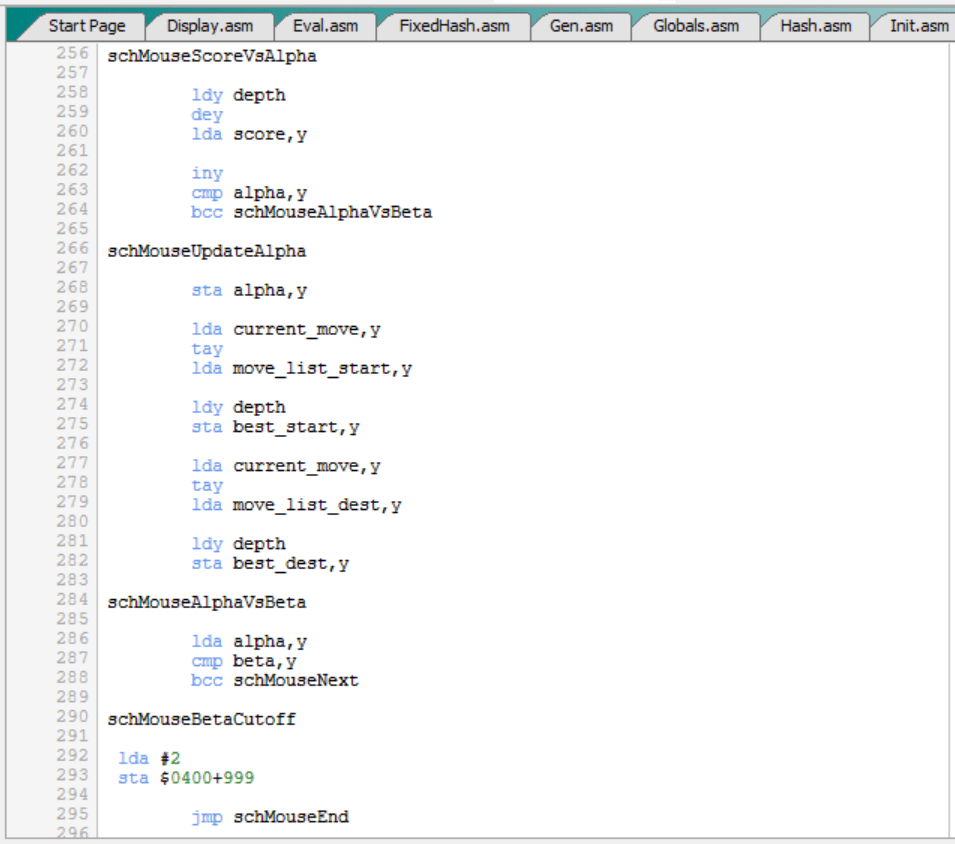
Es decir:
- Compara el valor de “score” con el valor de “alpha”.
- Si “score” es estrictamente menor que “alpha” (bcc), entonces no es necesario actualizar “alpha”, y vamos directamente a comparar a comparar “alpha” con “beta” (etiqueta “schMouseAlphaVsBeta”).
- En caso contrario, es decir, si “score” es mayor o igual que “alpha”, entonces (etiqueta “schMouseUpdateAlpha”) actualizamos “alpha” con el valor de “score” y el mejor movimiento (“best_move_start”, “best_move_dest”) con el valor del movimiento recién probado / deshecho (“move_list_start”, “move_list_dest”).
En ambos casos, tanto si actualizamos “alpha” como si no (en el proceso de cálculo del máximo entre “score” y “alpha”), lo siguiente según el pseudocódigo de la búsqueda alfa – beta es comparar alfa con beta, para determinar si hay una “poda beta”. Y esto es precisamente lo que hace ahora la rutina “searchMouse”:
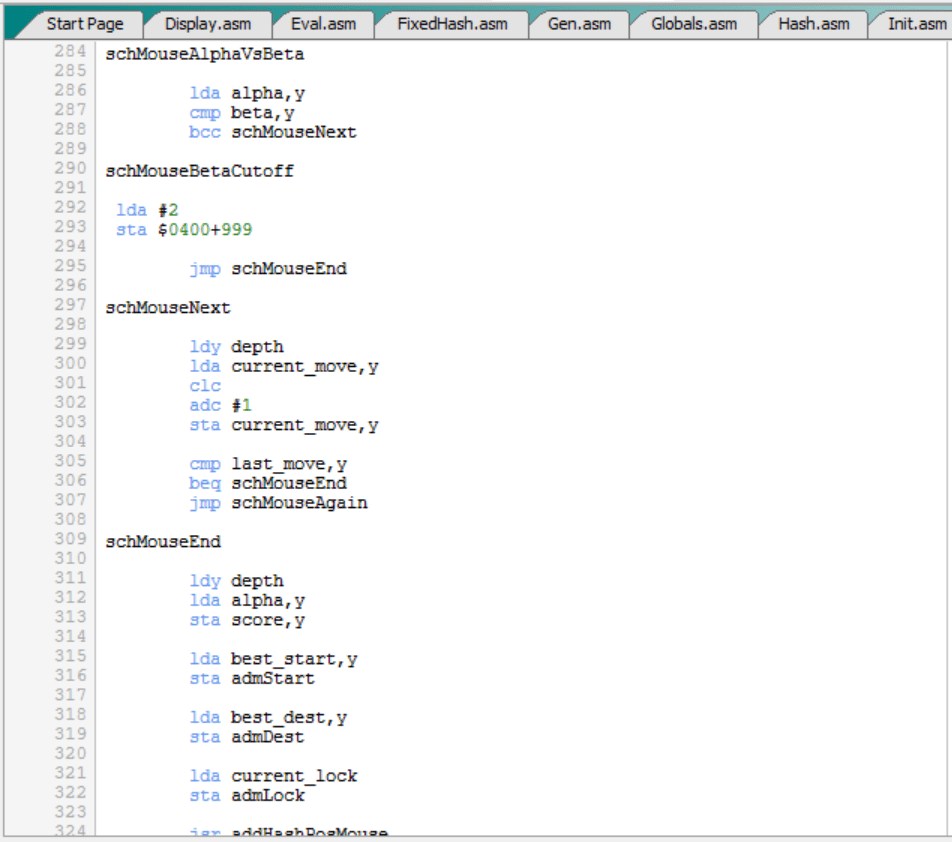
Es decir:
- Compara “alpha” con “beta”.
- Si “alpha” es estrictamente menor (bcc) salta a la etiqueta “schMouseNext”, que lo que hace es probar el siguiente movimiento del ratón (etiqueta “schMouseAgain”), salvo que sea el último de la lista (etiqueta “schMouseEnd”).
- En caso contrario, es decir, si “alpha” es mayor o igual que “beta”, entonces se produce una “poda beta” (etiqueta “schMouseBetaCutoff”), lo cual señalizamos poniendo el valor 2 = B (de beta) en la posición de pantalla $0400+999 = $07e7 = 2023, es decir, en la esquina inferior derecha de la pantalla. Además, como no hace falta seguir probando movimientos, saltamos a “schMouseEnd”, igual que si hubiéramos llegado al final de la lista de movimientos posibles.
Por último, la rutina “searchMouse” hace esto (etiqueta “schMouseEnd”):

Es decir, tanto si hemos llegado al final de la lista de movimientos posibles como si se ha producido una “poda beta”:
- Devuelve el valor de “alpha” en “score”.
- Y mete el mejor movimiento (“best_move_start”, “best_move_dest”) en la tabla hash del ratón con “addHashPosMouse”.
En fin, complejillo, pero se puede seguir. Cualquier función recursiva es compleja de entender, pero es que la búsqueda alfa – beta es especialmente compleja. Y encima en ensamblador…
Subrutina “searchCats”:
Como ya se ha comentado varias veces, la subrutina “searchCats” es totalmente análoga a “searchMouse”, siendo las principales diferencias:
- Los ratones son el bando minimizador.
- Calcula el mínimo entre “score” y “beta”.
- En caso de producirse poda, es una “poda alfa”.
- Devuelve “beta” y no “alpha”.
Por lo demás, es lo mismo…
Nueva rutina “thinkMax”:
Ahora que ya tenemos la rutina “search” lo siguiente es usarla y, como hemos dicho, en primera instancia la usaremos “a máxima profundidad”. Esto se hace desde la rutina “thinkMax”, que también está en el nuevo fichero “Search.asm”:
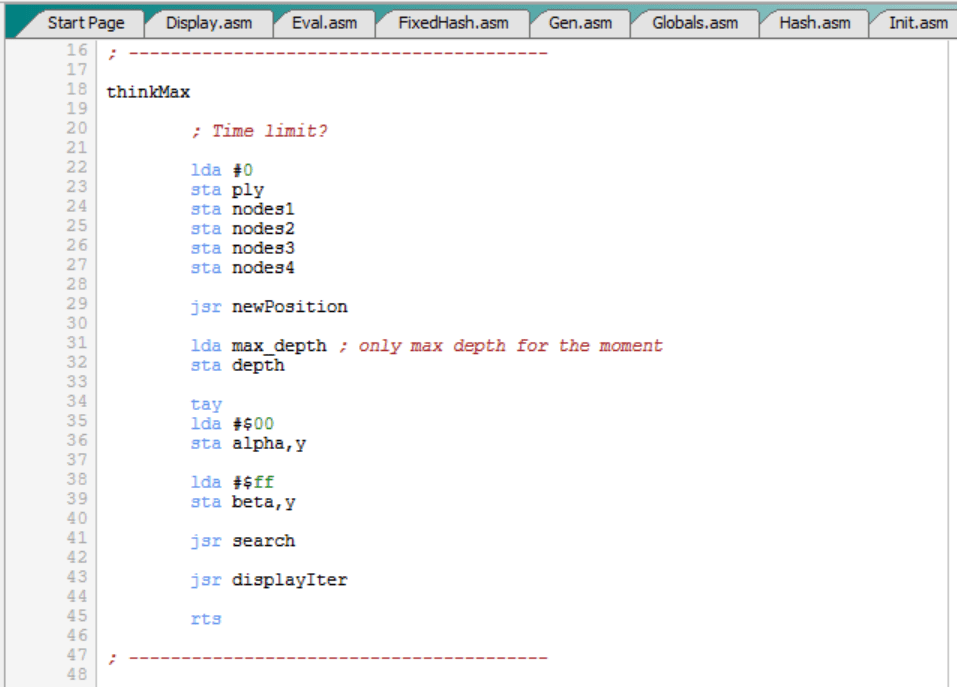
Es decir, la rutina “thinkMax”:
- Inicializa a cero “ply”, porque vamos a empezar a desarrollar el árbol de juego para decidir el siguiente movimiento.
- Inicializa a cero el número de nodos analizados (4 bytes).
- Llama a la rutina “newPosition”, que vimos hace unas cuantas entradas, y que básicamente preparaba todo para el desarrollo del árbol de juego y la decisión de la siguiente jugada.
- Llama a la rutina “search” con depth = max_depth, alpha = $00 y beta = $ff, es decir, que alfa y beta toman sus valores iniciales (menos infinito y más infinito respectivamente) y el análisis se va a realizar a máxima profundidad (“max_depth”).
Que el análisis se vaya a realizar “a máxima profundidad” no quiere decir que sea a una profundidad altísima (ej. 1000), o a la máxima profundidad que soporte el C64, sino a la profundidad o nivel de dificultad elegido por el usuario desde el programa principal (“Main.asm”).
Dicho de otro modo, todavía no tenemos “profundización iterativa”. No tenemos un bucle que vaya llamando a “search” para depth = 1, depth = 2, depth = 3, …, depth = max_depth. Vamos a “max_depth” directamente.
Por último, tras llamar a “search” para decidir la mejor jugada, la rutina “thinkMax” termina llamando a la rutina “displayIter”.
Nueva rutina “displayIter”:
“displayIter” es una rutina sencilla del fichero “Search.asm” que básicamente muestra información por pantalla sobre el proceso de búsqueda:
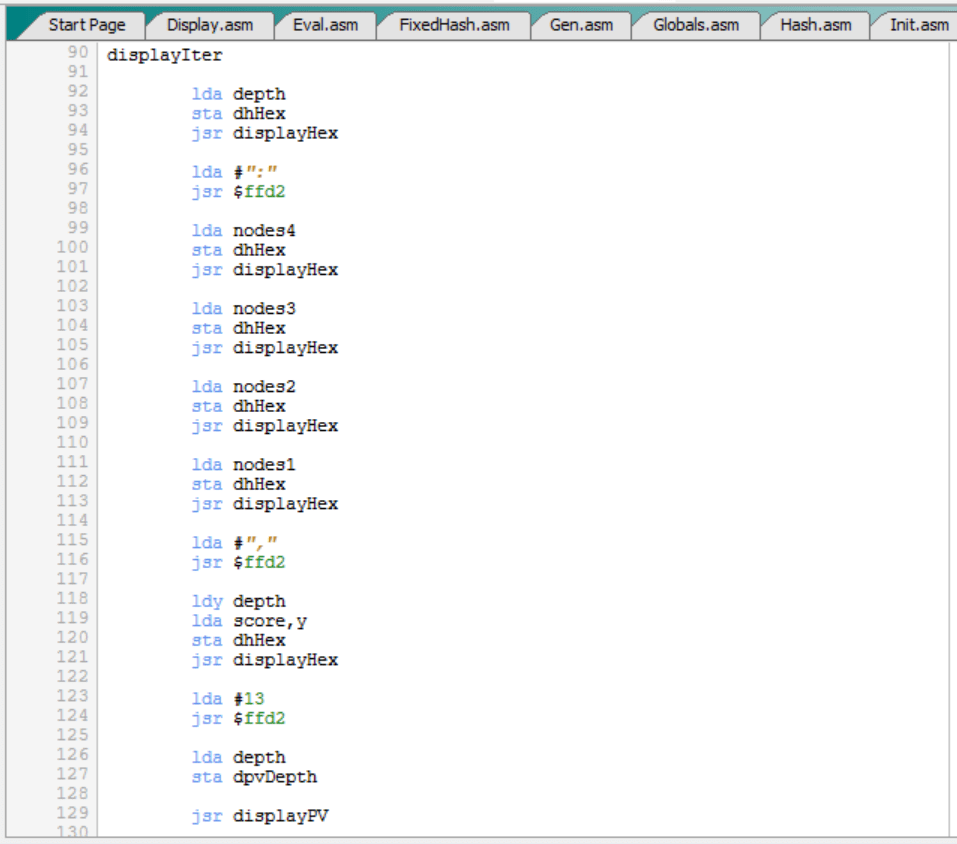
Como se puede ver, “displayIter” muestra por pantalla:
- La profundidad de búsqueda “depth”.
- El número de nodos analizados o desarrollados.
- La puntuación obtenida durante el proceso de búsqueda.
- Y la variante principal, es decir, la secuencia de jugadas que, según el C64, es la mejor secuencia de jugadas para ambos bandos.
Lo mejor de todo esto es que el C64 nos va contando cómo piensa que va a discurrir la partida. Nos da pistas de qué es lo que está pensando. Esto lo hace con la rutina “displayPV”.
Nueva rutina “displayPV”:
“PV” viene de variante principal o “principal variation” en inglés. Y como ya comentamos hace tiempo, la variante principal es la secuencia de jugadas que el C64 piensa que va a tener lugar, puesto que entiende que son las mejores jugadas para uno y otro bandos.
Y como la rutina “search” va eligiendo la mejor jugada para cada tablero (“best_start”, “best_dest”), y la almacena en las tablas hash con “addHashPosMouse” o “addHashPosCats”, según el turno, el resultado es que la variante principal la tenemos en las tablas hash.
Por tanto, la rutina “displayPV”, que es del fichero “Search.asm”, tan sólo tiene que ir a las tablas hash para consultar la variante principal:
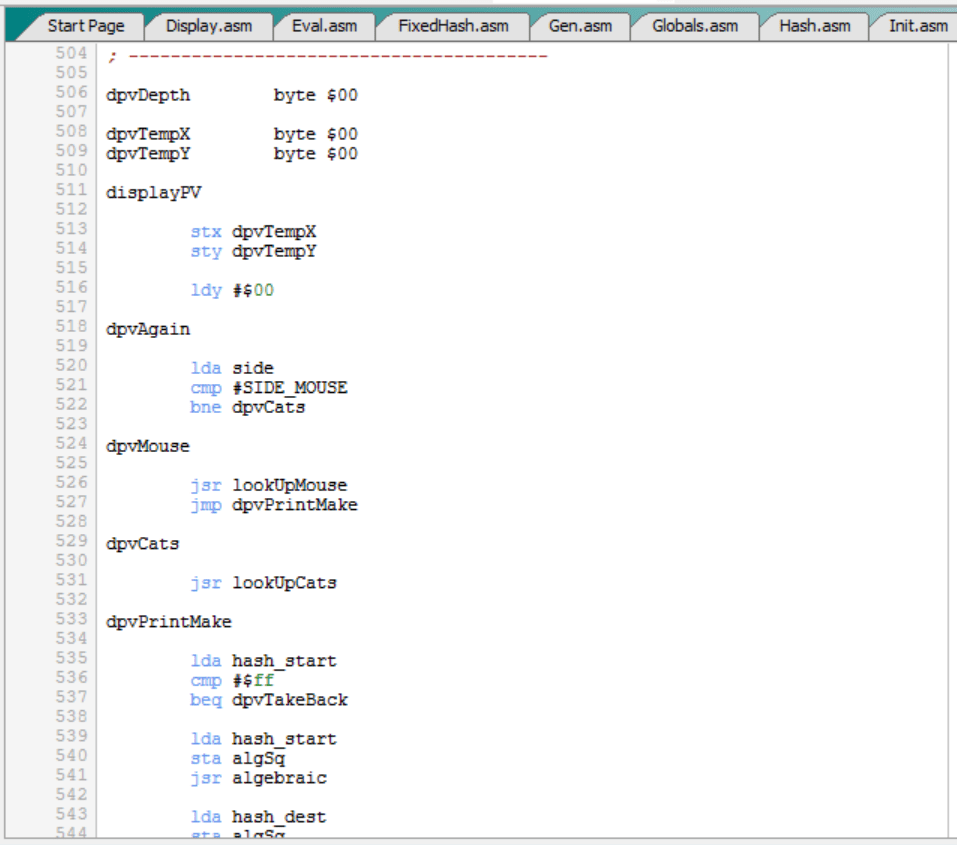
Es decir, la rutina “displayPV”:
- Recibe el número de jugadas de la variante principal (“depth”).
- Mira de quién es el turno con “side”.
- Si es el turno es del ratón busca el tablero actual en la tabla hash del ratón con “lookUpMouse”.
- Si el turno es de los gatos busca el tablero actual en la tabla hash de los gatos con “lookUpCats”.
- En ambos casos, se supone que el mejor movimiento a partir del tablero actual nos retorna en (“hash_start”, “hash_dest”) desde la tabla hash consultada, ya sea la tabla hash de ratón o gatos.
Y sigue así (etiqueta “dpvPrintMake”):
Es decir:
- Primero mira si el movimiento devuelto (“hash_start”, “hash_dest”) es válido. Esto lo hace comparando “hash_start” contra $ff, que es el valor con el que se inicializan “hash_start” y “hash_dest”.
- Si el movimiento es válido (diferente de $ff), imprime las casillas origen y destino con la rutina “algebraic”. Además, aplica el movimiento con “makeMove”. Esto lo hace para avanzar en la variante principal, es decir, para poder consultar el siguiente tablero y el siguiente movimiento de la variante principal. Esto se repite hasta alcanzar “depth”, es decir, hasta terminar el número de movimientos de la variante principal.
- Si el movimiento no es válido (igual a $ff) o, dicho de otro modo, si en la tabla hash no hay un movimiento para el tablero consultado, pasamos directamente a la fase de deshacer con “takeBack” los movimientos de la variante principal. Esto es la etiqueta “dpvTakeBack”.
En definitiva, y dicho de forma simple, la rutina “displayPV” simula que se van ejecutando los movimientos de la variante principal, que están almacenados en las tablas hash. Digo “simula” porque el objeto de esta ejecución es simplemente ir consultando los sucesivos tableros y los movimientos asociados, para imprimirlos e informar al usuario, y termina deshaciendo los mismos.
Nuevo programa principal:
Como siempre, todo esto (“search”, “thinkMax”, “displayIter”, “displayPV”, …) hay que probarlo, para lo que hacemos un nuevo programa principal:

Este nuevo programa principal:
- Llama a la rutina “setup”, que genera las tablas aleatorias que sirven de base para obtener los hashes con “randomize”, inicializa la partida con “initBoard” y da valor a algunas variables importantes del juego, como “max_depth” (más adelante este valor se lo pediremos al usuario).
- Llama a la rutina “displayBoard” para mostrar el tablero.
- Y finalmente llama a “thinkMax” para lanzar el proceso de búsqueda (“search”) a máxima profundidad.
El resultado después de pocos minutos de ejecución es así:
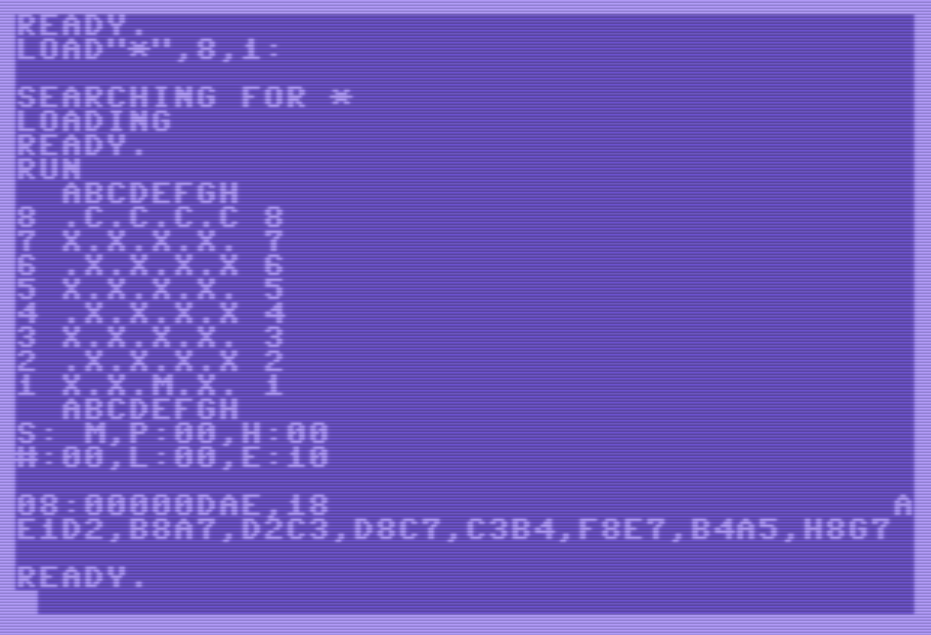
Es decir, para una profundidad de análisis de 8 movimientos (en “setup” se configura max_depth = 8), se analizan o desarrollan $0dae = 3.502 nodos, y el C64 decide que la variante principal es:
- E1D2.
- B8A7.
- D2C3.
- D8C7.
- C3B4.
- F8E7.
- B4A5.
- H8G7.
Es decir, el C64 piensa que esos son los movimientos que van a tener lugar porque, conforme a la función de evaluación “eval” que se ha programado, esos son los mejores movimientos para uno y otro bandos. Y si eso efectivamente ocurriera acabaríamos llegando a un tablero de valor $18 = 24.
Obsérvese cómo el ratón siempre avanza, al menos de momento que es posible, ya que eso es lo que hace subir su puntuación (jugador maximizador). Y obsérvese también que los gatos avanzan en formación, ya que hacerlo de otra manera reduciría más su puntuación que, al actuar como sustraendo (ev = $80 + evMouse – evCats), tendría como efecto que la puntuación “ev” sería mayor. Y eso no interesa a los gatos porque son el bando minimizador.
Al menos esto es lo que piensa el C64 que va ocurrir. Cuestión diferente es lo que decida el jugador humano cuando le toque jugar. Puede jugar a perder, jugar al despiste, hacer jugadas heterodoxas, jugadas mejores que las que tiene programadas el C64, etc.
También es muy interesante analizar el número de nodos buscados o desarrollados, que vale $0dae = 3.502. Este valor es muy inferior al número de nodos que cabría esperar aplicando la búsqueda minimax. Esto es gracias a las podas que produce la búsqueda alfa – beta.
Estas podas se marcan con las letras “A” (poda alfa) y “B” (poda beta) que aparecen en la esquina inferior derecha de la pantalla, y que al hacer scroll suben hacia arriba. Esto se puede mejorar definiendo contadores de podas alfa y beta, y mostrando esta información en “displayIter”, como ya se hace con la profundidad de análisis, el número de nodos desarrollados, o la evaluación final. De momento, como sólo se trata de confirmar que efectivamente hay podas, nos vale como está.
En la entrada siguiente le daremos una vuelta de tuerca para, mejor que ir directamente a la máxima profundidad, vayamos paso a paso, lo que nos permitirá mejorar la ordenación de movimientos y la poda.
Código del proyecto: RYG3-07
