Siguiendo con el libro “Endless Loop”, he leído un par de curiosidades sobre BASIC que me ha parecido interesante compartir.
La primera es uno de los programas en BASIC más famosos de toda la historia, al estilo de aquellas competiciones que se hacían en C para condensar aplicaciones completas en una sola línea de código.
El programa en BASIC es así (en BASIC del C64, of course):
Yo creo que todos los que cacharreamos con el C64 en los 80 nos acordaremos del curioso resultado:
La segunda es un libro de juegos en BASIC que en su momento se hizo muy famoso y que, por lo visto, inspiró a varios de los grandes pioneros de la informática personal como Steve Wozniak.
Se titulaba “101 Games in BASIC”, del autor David Ahl, y era una recopilación de juegos en BASIC:
El libro tenía los típicos listados de BASIC que muchos nos picamos incansablemente en aquella época inolvidable. Y como BASIC tenía muchos dialectos, a veces no quedaba otra que adaptar un poco el código el ordenador que tuvieras.
El libro tuvo varias ediciones, como la titulada “BASIC computer games”, y todavía se puede encontrar por ahí en Internet en sitios como Archive.org:
Este blog es sobre el C64, pero sobre todo ensamblador y código máquina. Últimamente también le hemos pegado al C con cc65.
El motivo para centrarnos en el código máquina es que era mucho menos accesible que BASIC. Los cuarentones (por no decir cosas peores, jaja) que ahora disfrutamos de la informática retro, en los 80, teníamos 15 años. A esa edad el BASIC se medio entendía, pero el código máquina parecía magia. Al menos para mí. Por eso, las cuentas pendientes eran con el código máquina.
BASIC apenas lo hemos tocado. Y, sin embargo, tiene una historia mucho más interesante de lo que podría parecer. BASIC no apareció con el ZX Spectrum, ni con el C64, ni con ningún otro microordenador. Tampoco con Bill Gates ni con Microsoft. Surgió en la universidad americana de Dartmouth a mitad de los años 60. Y surgió vinculado a los sistemas de tiempo compartido, que fueron los primeros ordenadores que se podían usar a la vez por varios usuarios. Vamos, que fue un avance importante en su tiempo, aunque ahora nos parece un lenguaje de risa.
Todo esto lo estoy descubriendo en el libro “Endless Loop” de Mark Jones Lorenzo:
Es un libro interesante, pero sólo lo recomendaría a quien le interese la historia de la informática. Si lo que buscáis es información técnica sobre el C64 o sobre programación en BASIC, ese no es el contenido del libro.
En el libro se cita el documental “Birth of BASIC”, publicado por Dartmouth University en 2014, por el 50 aniversario del nacimiento de BASIC:
Son apenas 40 minutos y en inglés, pero está curioso echarle un vistazo. Nuestro entrañable BASIC nació como una cosa bastante más seria y académica de lo que nos parece hoy, en los tiempos de la IA y del Python.
Dicen que desde hace unos años Python es uno de los lenguajes más populares. Sin embargo, ayer en Amazon el ranking de ventas bajo la categoría «Programación y desarrollo de software» estaba así:
En este volumen IV se revisa a fondo este aspecto tan interesante como poco conocido: la programación en C para el Commodore 64. Más concretamente, se revisan aspectos generales de cc65, como cómo compilar y enlazar, cómo es el entorno de ejecución, cómo usar librerías específicas para hacer entrada / salida por pantalla, manejar el joystick o el ratón, hacer gráficos bitmap, etc.
También se revisa al lenguaje de programación C propiamente dicho, si bien esta tarea merecería un libro en sí mismo.
Por último, también se desarrolla un juego clásico en C, como es el Tetris. Esto permite al lector hacerse una buena idea de lo mucho que se puede hacer en C para el C64.
A lo largo de las últimas 40 entradas le hemos dado un buen repaso a un aspecto tan interesante como poco conocido: la programación en C para el C64.
Tradicionalmente el C64 se ha programado en BASIC o en código máquina / ensamblador, pero no en C u otros lenguajes. Sin embargo, programar en C para el C64 es posible desde hace años gracias a cc65, un entorno de programación C para ordenadores con el microprocesador 6502 / 6510, como nuestro querido C64.
Más concretamente, hemos visto aspectos generales de cc65, como cómo compilar y enlazar, cómo es el entorno de ejecución, cómo usar librerías específicas para hacer entrada / salida por pantalla, manejar el joystick o el ratón, hacer gráficos bitmap, etc.
También le hemos dado un buen repaso al lenguaje C, si bien esta es una tarea que se merece un blog o un libro en sí mismo.
Para rematar, en poco más de 10 pasos hemos desarrollado un juego clásico en C, como es el Tetris. Sin duda, la implementación es mejorable (ej. se pueden usar caracteres personalizados, se le puede meter sonido, reducir el parpadeo, etc.), pero nos da una buena idea de lo mucho que se puede hacer en C para el C64.
C está a medio camino entre el ensamblador / código máquina y el BASIC. Por un lado, es de alto nivel, como el BASIC, pero admite mucha más estructura. Por otro lado, es compilado, no interpretado, lo que significa que en última instancia lo que se genera y ejecuta es código máquina, que es mucho más rápido que BASIC. Y con C es muy fácil acceder a memoria y a registros como los del VIC o el SID. En definitiva, lo mejor de ambos mundos, a mi entender.
En el fondo, si os fijáis bien, casi se puede leer el código máquina entre las líneas de C…
Espero que lo hayáis disfrutado tanto como yo y que sirva para inspirar vuestros propios proyectos,
Como última mejora del juego, vamos a hacer que las fichas puedan caer a plomo.
La caída a plomo se produce cuando el jugador cree que ya ha colocado la ficha en la posición y rotación correctas. En ese momento, si pulsa el joystick hacia abajo, la ficha cae rápidamente, sin posibilidad de moverla o rotarla más.
Hasta ahora, la ficha podía estar en uno de dos estados:
O inactiva (FICHA_ESTADO_INACTIVA), en cuyo caso se activaba y pintaba una ficha nueva.
O activa (FICHA_ESTADO_ACTIVA), en cuyo caso la ficha caía, se podía mover y rotar, si el jugador así lo quería, y se acumulaba al llegar al fondo del tablero.
Pues bien, ahora vamos a definir un tercer estado FICHA_ESTADO_PLOMO, que no deja de ser una especie de variante del estado FICHA_ESTADO_ACTIVA. Cuando la ficha esté en este nuevo estado caerá sin retardo, es decir, rapidito, y sin posibilidad de que el jugador la mueva o la rote.
Los cambios se concentran en el fichero tetris_main.c.
Fichero tetris_main.c:
En primer lugar, tenemos que detectar que el jugador ha tirado hacia abajo del joystick:
Cuando ocurre lo anterior, la ficha deja de estar en estado FICHA_ESTADO_ACTIVA y pasa a estar en estado FICHA_ESTADO_PLOMO. El nuevo estado se reconoce y se trata en el bucle de juego:
Y, por último, tenemos la nueva función ficha_plomo() que viene a ser equivalente a ficha_actualiza(), pero sin retardo y sin posibilidad de mover ni rotar:
Resultado:
El resultado es que el jugador ya puede lanzar la ficha a plomo, una vez que piensa que ya la tiene correctamente colocada. Esta función está disponible en la mayoría de implementaciones de Tetris.
Cuando diseñamos la caída de las fichas vimos que, para que la caída no fuera muy rápida, convenía introducir un retardo (recordemos la variable ret):
Pues bien, lo que vamos a hacer ahora es complicar un poco el juego para que ese retardo sea mayor o menor en función de un nivel que elige el jugador. Lógicamente, a mayor nivel menor retardo o mayor velocidad.
De paso, vamos a aprovechar también para mover las variables líneas, puntos y max_puntos desde el fichero tetris_tablero.c al fichero tetris_main.c.
Líneas, puntos y max_puntos:
Las variables líneas, puntos y max_puntos las pusimos en su momento, no sin dudas, en el fichero tetris_tablero.c. Recapacitando, lo cierto es que esas variables tienen más que ver con el proceso principal del juego y su control que con el tablero.
Por este motivo, estas variables las movemos desde el fichero tetris_tablero.c al fichero tetris_main.c. Y algo similar hacemos con las funciones asociadas a estas variables:
La anterior función tablero_inicializa_puntos() se diluye en la función inicializa_partida().
Y la anterior función tablero_pinta_puntos() se convierte en la función pinta_puntos().
Bueno, esto no es un cambio muy profundo. Es más bien una reubicación de funcionalidad.
Nivel y retardo:
Este es el cambio importante. Consiste en que el jugador elige un nivel y, en función de ese nivel, así será el retardo de la caída.
Todo esto lo controlamos con las nuevas variables nivel y ret_max:
La variable nivel la inicializamos a 1 en la inicialización del juego, pero luego el jugador podrá cambiar ese valor:
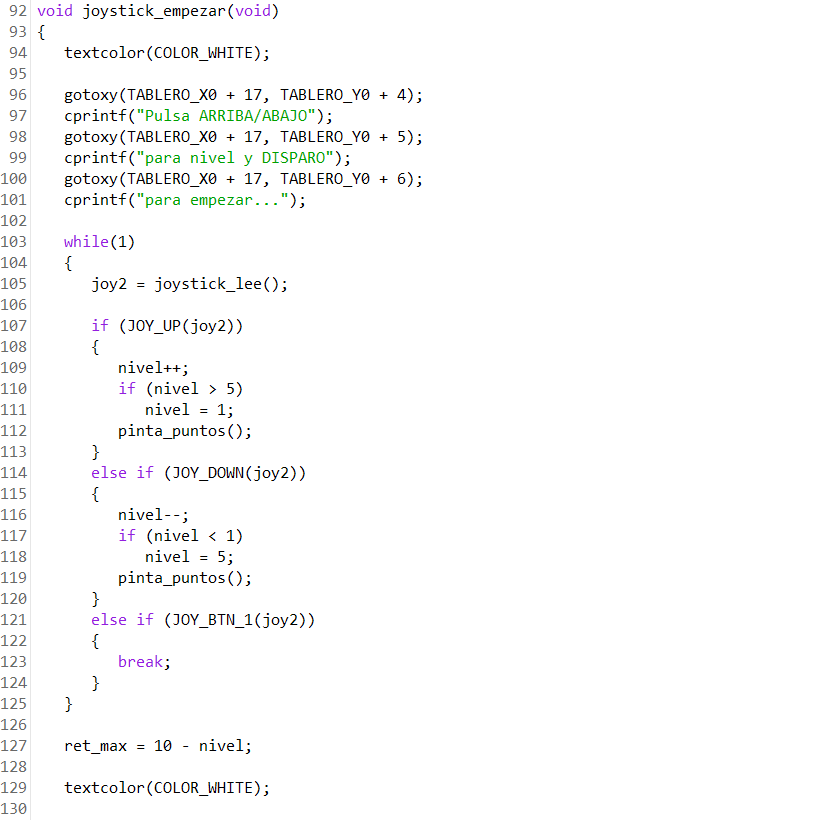
La forma de cambiar el nivel es mediante una nueva implementación de la función joystick_empezar():
Ahora, además de pulsar disparo para empezar el juego, el jugador podrá mover el joystick arriba para subir el nivel (hasta 5) o abajo para bajarlo (hasta 1). Posteriormente, el retardo (nueva variable ret_max) se define como:
ret_max = 10 – nivel
Y ya sólo que cambiar la función ficha_actualiza() para que, en vez de usar un retardo fijo de 10 iteraciones, utilice un retardo variable ret_max que depende del nivel elegido:
Resultado:
El resultado es que ahora el jugador puede elegir el nivel y, en función del nivel, así es el retardo con que ocurre la caída de las fichas (nivel 1 => retardo de 9 iteraciones; nivel 5 => retardo de 5 iteraciones):
Ahora que ya somos capaces de detectar el final de partida, el siguiente paso es que el juego sea multipartida, es decir que el jugador pueda jugar varias partidas seguidas antes de terminar el juego o apagar el C64.
De paso, suele ser habitual llevar cuenta de la puntuación máxima (recordemos que hace un par de entradas empezamos a controlar líneas y puntos). No es algo tan completo como llevar un ranking de jugadores y puntuaciones, pero algo es algo.
Para conseguir lo anterior, los cambios se focalizan en el programa principal, es decir, en tetris_main.c. No obstante, también hay algún pequeño retoque en tetris_tablero.c.
Fichero tetris_tablero.c:
En este fichero complementamos las variables líneas y puntos con una nueva variable max_puntos:
Ya dijimos en algún apartado anterior que estas variables las reubicaremos más adelante.
Por otro lado, también modificamos la función tablero_pinta_puntos() para que, además de pintar las líneas y los puntos, también pinte el máximo de puntos:
Por último, en la función tablero_filas_llenas(), que sirve para detectar las filas llenas y colapsarlas, si la puntuación actual supera el máximo, tenemos que actualizar el máximo:
Esto también podría hacerse al final de cada partida, pero casi está mejor hacerlo sobre la marcha.
Fichero tetris_main.c:
Los cambios fuertes están en este segundo fichero. Para empezar, dejamos de tener una inicialización única (función inicializa()) para tener una inicialización del juego (nueva función inicializa_juego()) y una inicialización de la partida (nueva función inicializa_partida()).
La primera función inicializa todo aquello que tiene que inicializarse una única vez:
Carga el driver del joystick.
Cambia los colores del fondo y del borde.
Y pone max_puntos a cero.
La segunda, por su lado, inicializa todo aquello que hay que inicializar en cada partida (recordemos que ahora vamos a tener varias partidas):
Borra la pantalla.
Inicializa el tablero vacío y lo pinta.
Inicializa los puntos y los pinta.
Inicializa la ficha.
Por otro lado, el cambio principal está en el bucle de juego. Si antes era así:
Ahora pasa a ser así:
Es decir, ahora tenemos:
Un bucle interior que es propiamente el bucle de juego.
Y un bucle exterior que es el bucle de las diferentes partidas.
Si nos fijamos en el bucle exterior, que es el nuevo:
Inicializa la partida con inicializa_partida().
Con joystick_empezar() espera a que el jugador pulse el disparo para empezar la partida.
Tiene lugar la partida, es decir, el bucle de juego.
Cuando termina la partida, con joystick_continuar() espera a que el jugador pulse el disparo para continuar con otra partida.
Las funciones joystick_empezar() y joystick_continuar() son nuevas, y básicamente muestran un mensaje, que es diferente en cada función, esperan a que el jugador pulse el disparo, y borran el mensaje:
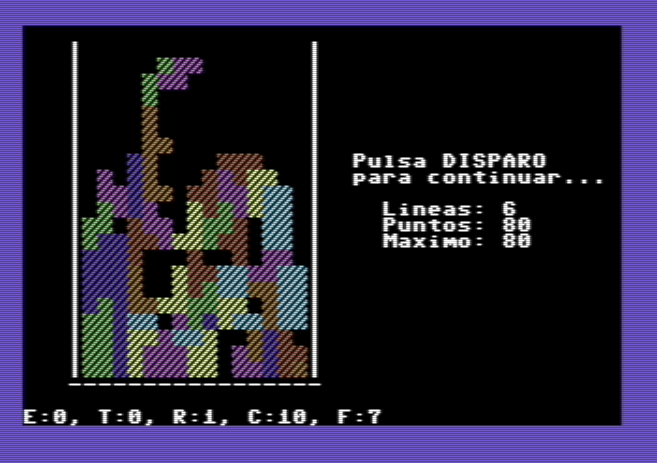
Resultado:
El resultado es que ahora ya es posible jugar varias partidas seguidas. Antes de cada partida, el jugador tiene que pulsar el disparo, y al terminar la partida también, para así continuar con otra partida.